1.使用Shell
fs命令:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
root@master:~# hadoop fs Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>] [-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] <path> ...] [-cp [-f] [-p | -p[topax]] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] <path> ...] [-expunge] [-find <path> ... <expression> ...] [-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getfattr [-R] {-n name | -d} [-e en] <path>] [-getmerge [-nl] <src> <localdst>] [-help [cmd ...]] [-ls [-d] [-h] [-R] [<path> ...]] [-mkdir [-p] <path> ...] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal <src> <localdst>] [-mv <src> ... <dst>] [-put [-f] [-p] [-l] <localsrc> ... <dst>] [-renameSnapshot <snapshotDir> <oldName> <newName>] [-rm [-f] [-r|-R] [-skipTrash] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...] [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setfattr {-n name [-v value] | -x name} <path>] [-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] <file>] [-test -[defsz] <path>] [-text [-ignoreCrc] <src> ...] [-touchz <path> ...] [-truncate [-w] <length> <path> ...] [-usage [cmd ...]] Generic options supported are -conf <configuration file> specify an application configuration file -D <property=value> use value for given property -fs <local|namenode:port> specify a namenode -jt <local|resourcemanager:port> specify a ResourceManager -files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster -libjars <comma separated list of jars> specify comma separated jar files to include in the classpath. -archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines. The general command line syntax is bin/hadoop command [genericOptions] [commandOptions] root@master:~# |
hadoop fs 为固定前缀,接着是-命令,后面根据情况可能是各种命令参数,如副指令、路径。
0)打印文件列表 ls
(1)标准写法
|
1 2 |
hadoop fs -ls hdfs:/ #hdfs: 明确说明是HDFS系统路径 |
-rw-r--r-- 2 root supergroup 4855027 2015-05-07 10:43 / dead_train.txt
权限 副本数 用户 用户组 大小byte 创建日期 创建时间 路径 文件名
(2)简写
|
1 2 |
hadoop fs -ls / #默认是HDFS系统下的根目录 |
(3)打印指定子目录
|
1 2 |
hadoop fs -ls /package/test/ #HDFS系统下某个目录 |
(4)XXXXX
|
1 2 |
hadoop fs -ls -d / #-d参数没弄明白,使用后打印一条信息 |
drwxr-xr-x - root supergroup 0 2015-05-07 11:12 /
(5)最大单位打印
|
1 2 |
hadoop fs -ls -h / #文件大小显示为最大单位 |
-rw-r–r– 2 root supergroup 4.6M 2015-05-07 10:43 / dead_train.txt
权限 副本数 用户 用户组 大小 创建日期 创建时间 路径 文件名
(6)递归打印
|
1 2 |
hadoop fs -ls -R / #如果有子目录,则递归打印 |
(7)多个打印参数
|
1 2 |
hadoop fs -ls -h -R / #递归打印并且最大单位打印文件 |
1)上传文件/目录 put、copyFromLocal
从主机本地系统到集群HDFS系统。
(1)put
<1>上传新文件
|
1 2 3 4 |
hdfs fs -put file:/root/test.txt hdfs:/ #上传本地test.txt文件到HDFS根目录,HDFS根目录须无同名文件,否则“File exists” hdfs fs -put test.txt /test2.txt #上传并重命名文件。 hdfs fs -put test1.txt test2.txt hdfs:/ #一次上传多个文件到HDFS路径。 |
<2>上传文件夹
|
1 2 |
hdfs fs -put mypkg /newpkg #上传并重命名了文件夹。 |
<3>覆盖上传
|
1 2 |
hdfs fs -put -f /root/test.txt / #如果HDFS目录中有同名文件会被覆盖 |
(2)copyFromLocal
和put的用法雷同。
<1>上传文件并重命名
|
1 2 |
hadoop fs -copyFromLocal file:/test.txt hdfs:/test2.txt |
<2>覆盖上传
|
1 2 |
hadoop fs -copyFromLocal -f test.txt /test.txt |
2)下载文件/目录 get、copyToLocal
从集群HDFS到本地文件系统。
(1)get
<1>拷贝文件到本地目录
|
1 2 |
hadoop fs -get hdfs:/test.txt file:/root/ |
<2>拷贝文件并重命名。可以简写
|
1 2 |
hadoop fs -get /test.txt /root/test.txt |
(2)copyToLocal
<1>拷贝文件到本地目录
|
1 2 |
hadoop fs -copyToLocal hdfs:/test.txt file:/root/ |
<2>拷贝文件并重命名。可以简写
|
1 2 |
hadoop fs -copyToLocal /test.txt /root/test.txt |
3)拷贝文件/目录 cp
<1>从本地到HDFS,同put
|
1 |
hadoop fs -cp file:/test.txt hdfs:/test2.txt |
<2>从HDFS到HDFS
|
1 2 |
hadoop fs -cp hdfs:/test.txt hdfs:/test2.txt hadoop fs -cp /test.txt /test2.txt |
4)移动文件 mv
|
1 2 3 |
hadoop fs -mv hdfs:/test.txt hdfs:/dir/test.txt hadoop fs -mv /test.txt /dir/test.txt |
5)删除文件/目录 rm
<1>删除指定文件
|
1 2 |
hadoop fs -rm /a.txt |
<2>删除全部txt文件
|
1 2 |
hadoop fs -rm /*.txt |
<3>递归删除全部文件和目录
|
1 2 |
hadoop fs -rm -R /dir/ |
6)读取文件 cat
|
1 2 |
hadoop fs -cat /test.txt #以字节码的形式读取 |
7)读取文件尾部 tail
|
1 2 |
hadoop fs -tail /test.txt 尾部1K字节 |
8)创建空文件 touchz
|
1 2 |
hadoop fs - touchz /newfile.txt |
9)写入文件 appendToFile
|
1 2 |
hadoop fs - appendToFile file:/test.txt hdfs:/newfile.txt #读取本地文件内容追加到HDFS文件 |
10)创建文件夹 mkdir
|
1 2 3 |
hadoop fs -mkdir /newdir /newdir2 #可以同时创建多个 hadoop fs -mkdir -p /newpkg/newpkg2/newpkg3 #同时创建父级目录 |
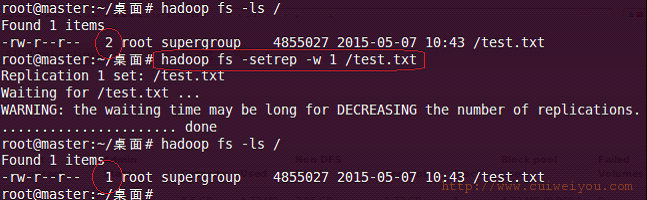
11)改变文件副本数 setrep
|
1 |
hadoop fs -setrep -R -w 2 /test.txt |
-R 递归改变目录下所有文件的副本数。
-w 等待副本数调整完毕后返回。可理解为加了这个参数就是阻塞式的了。
12)获取逻辑空间文件/目录大小 du
|
1 2 3 4 |
hadoop fs - du / #显示HDFS根目录中各文件和文件夹大小 hadoop fs -du -h / #以最大单位显示HDFS根目录中各文件和文件夹大小 hadoop fs -du -s / #仅显示HDFS根目录大小。即各文件和文件夹大小之和 |
13)获取HDFS目录的物理空间信息 count
|
1 2 |
hadoop fs -count -q / #显示HDFS根目录在物理空间的信息 |
-q 查看全部信息,否则只显示后四项。

2.使用JavaAPI
以下jar都可以从%hadoop_home%/share/hadoop/中找到
本例使用
Eclipse IDE for Java Developers版eclipse-java-luna-SR2-linux-gtk-x86_64.tar.gz
下载
http://www.eclipse.org/downloads
在debian中安装
tar -zxvf eclipse-java-luna-SR2-linux-gtk-x86_64.tar.gz
注意,首先从shell启动HDFS。
对于shell的代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 |
public class TestHdfs { private FileSystem hdfs; private Configuration conf; @Test // 1 创建空文件 public void testCreateNewFile() throws Exception { conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); // core-site.xml中到配置 conf.set("mapred.jop.tracker", "localhost:9001"); hdfs = FileSystem.get(conf); //创建空文件 hdfs.createNewFile(new Path("hdfs:/newfile.txt")); hdfs.close(); } @Test // 2 遍历指定目录及其子目录内的文件 public void testListFiles() throws Exception { // 1.配置器 conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); // 2.文件系统 hdfs = FileSystem.get(conf); // 3.遍历HDFS上的文件 RemoteIterator<LocatedFileStatus> fs = hdfs.listFiles(new Path("hdfs:/"), true); while(fs.hasNext()){ System.out.println(fs.next()); } hdfs.close(); } @Test // 3 查看目录/文件状态 public void listStatus() throws Exception { // 1.创建配置器 conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); // 2.创建文件系统 hdfs = FileSystem.get(conf); // 3.遍历HDFS上的文件和目录 FileStatus[] fs = hdfs.listStatus(new Path("hdfs:/")); if (fs.length > 0) { for (FileStatus f : fs) { showDir(f); } }else{ System.out.println("nothing..."); } hdfs.close(); } // 4 判断是目录,还是文件 private void showDir(FileStatus fs) throws Exception { Path path = fs.getPath(); System.out.println(path); // 如果是目录 if (fs.isDirectory()) { FileStatus[] f = hdfs.listStatus(path); if (f.length > 0) { for (FileStatus file : f) { showDir(file); } } } // 如果是文件 if (fs.isFile()){ //fs.getXXX(); long time = fs.getModificationTime(); System.out.println("HDFS文件的最后修改时间:"+new Date(time)); } } @Test // 5 判断存在 public void testExists() throws Exception { // 1.创建配置器 conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); //2.创建文件系统 hdfs = FileSystem.get(conf); //3.创建可供hadoop使用的文件系统路径 Path file = new Path("hdfs:/test.txt"); // 4.判断文件是否存在(文件目标路径) System.out.println("文件存在:" + hdfs.exists(file)); hdfs.close(); } @Test // 6 向文件写入数据 public void testAppend() throws Exception { conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); /* 在hdfs-site.xml中配置了没啥用 org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.protocol.AlreadyBeingCreatedException): Failed to APPEND_FILE /newfile.txt for DFSClient_NONMAPREDUCE_-610333487_1 on 127.0.0.1 because this file lease is currently owned by DFSClient_NONMAPREDUCE_1541357537_1 on 127.0.0.1 */ conf.set("dfs.client.block.write.replace-datanode-on-failure.policy" ,"NEVER" ); conf.set("dfs.client.block.write.replace-datanode-on-failure.enable" ,"true" ); /* java.io.IOException: Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try. (Nodes: current=[DatanodeInfoWithStorage[127.0.0.1:50010,DS-b1c29ca4-24f7-4447-a12b-5ae261663431,DISK]], original=[DatanodeInfoWithStorage[127.0.0.1:50010,DS-b1c29ca4-24f7-4447-a12b-5ae261663431,DISK]]). The current failed datanode replacement policy is DEFAULT, and a client may configure this via 'dfs.client.block.write.replace-datanode-on-failure.policy' in its configuration. */ conf.set("dfs.support.append", "true"); hdfs = FileSystem.get(conf); Path path = new Path("hdfs:/newfile.txt"); if (!hdfs.exists(path)) { hdfs.create(path); hdfs.close(); hdfs = FileSystem.get(conf); } FSDataOutputStream out = hdfs.append(path); out.write("4每次执行次方法只能有一个write语句?!!!\n".getBytes("UTF-8")); out.write("5每次执行次方法只能有一个write语句?!!!\n".getBytes("UTF-8")); out.close(); hdfs.close(); } @Test // 7 读文件 public void testOpen() throws Exception { conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); hdfs = FileSystem.get(conf); Path path = new Path("hdfs:/newfile.txt"); FSDataInputStream is = hdfs.open(path); FileStatus stat = hdfs.getFileStatus(path); byte[] buffer = new byte[Integer.parseInt(String.valueOf(stat.getLen()))]; is.readFully(0, buffer); is.close(); hdfs.close(); System.out.println(new String(buffer)); } @Test // 8 重命名文件 public void testRename() throws Exception { conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); hdfs = FileSystem.get(conf); //重命名:fs.rename(源文件,新文件) boolean rename = hdfs.rename(new Path("/newfile.txt"), new Path("/test.txt")); System.out.println(rename); hdfs.close(); } @Test // 8 删除目录/文件 public void testDelete() throws Exception { conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); hdfs = FileSystem.get(conf); //判断删除(路径,true=非空也删除。false=非空时不删除,抛RemoteException、IOException异常) boolean delete = hdfs.delete(new Path("hdfs:/test.txt"), true); System.out.println("执行删除:"+delete); //FileSystem关闭时执行 boolean exit = hdfs.deleteOnExit(new Path("/out.txt")); System.out.println("执行删除:"+exit); hdfs.close(); } @Test // 10 创建目录/文件。父目录不存在则直接创建 public void testCreate() throws Exception { conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); hdfs = FileSystem.get(conf); // 使用HDFS数据输出流(写)对象 在HDSF上根目录创建一个文件夹,其内再创建文件 FSDataOutputStream out = hdfs.create(new Path("hdfs:/vigiles/eminem.txt")); // 在文件中写入一行数据,必须使用UTF-8 out.write("痞子阿姆,Hello !".getBytes("UTF-8")); out.flush(); out = hdfs.create(new Path("/vigiles/alizee.txt")); out.write("艾莉婕,Hello !".getBytes("UTF-8")); out.close(); FSDataInputStream is = hdfs.open(new Path("hdfs:/vigiles/alizee.txt")); FileStatus stat = hdfs.getFileStatus(new Path("hdfs:/vigiles/alizee.txt")); byte[] buffer = new byte[Integer.parseInt(String.valueOf(stat.getLen()))]; is.readFully(0, buffer); is.close(); hdfs.close(); System.out.println(new String(buffer)); } @Test // 11 创建目录 public void testMkdir() throws Exception { conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); hdfs = FileSystem.get(conf); //创建目录 hdfs.mkdirs(new Path("hdfs:/eminem1")); hdfs.mkdirs(new Path("hdfs:/eminem2")); hdfs.mkdirs(new Path("hdfs:/eminem3")); hdfs.close(); } @Test // 12 文件备份状态 public void testGetFileBlockLocations() throws Exception { //1.配置器 conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); //2.文件系统 hdfs = FileSystem.get(conf); //3.已存在的,必须是文件 Path path = new Path("hdfs:/vigiles/alizee.txt"); //4.文件状态 FileStatus status = hdfs.getFileStatus(path); //5.文件块 //BlockLocation[] blockLocations = fs.getFileBlockLocations(status, 0, status.getLen()); //方法1,传入文件的FileStatus BlockLocation[] blockLocations = hdfs.getFileBlockLocations(path, 0, status.getLen()); //方法2,传入文件的Path int blockLen = blockLocations.length; System.err.println("块数量:"+blockLen); //如果文件不够大,就不会分块,即得到1 // 遍历文件块到信息 for (int i = 0; i < blockLen; i++) { //得到块文件大小 long sizes = blockLocations[i].getLength(); System.err.println("块大小:"+sizes); //按照备份数量得到全部主机名 String[] hosts = blockLocations[i].getHosts(); for (String host : hosts) { System.err.println("主机名:"+host); } //按照备份数量得到全部主机名 String[] names = blockLocations[i].getNames(); for (String name : names) { System.err.println("IP:"+ name); } } hdfs.close(); } @Test // 13 上传文件 public void testCopyFromLocalFile() throws Exception { // 1.创建配置器 conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); //2.创建文件系统 hdfs = FileSystem.get(conf); //3.创建可供hadoop使用的文件系统路径 Path src = new Path("file:/root/xx.txt"); //本地目录/文件 Path dst = new Path("hdfs:/"); //目标目录/文件 // 4.拷贝本地文件上传(本地文件,目标路径) hdfs.copyFromLocalFile(src, dst); System.out.println("文件上传成功至:" + conf.get("fs.default.name")); // 5.列出HDFS上的文件 FileStatus[] fs = hdfs.listStatus(dst); for (FileStatus f : fs) { System.out.println(f.getPath()); } hdfs.close(); } @Test // 14 下载文件到本地 public void testCopyToLocalFile() throws Exception { conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); conf.set("mapred.jop.tracker", "localhost:9001"); hdfs = FileSystem.get(conf); //创建HDFS源路径和本地目标路径 Path src = new Path("hdfs:/xx.txt"); //目标目录/文件 Path dst = new Path("file:/root/桌面/new.txt"); //本地目录/文件 //拷贝本地文件上传(本地文件,目标路径) hdfs.copyToLocalFile(src, dst); hdfs.close(); } } |
错误:
Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try.
原因:无法写入;我的环境中有3个datanode,备份数量设置的是3。在写操作时,它会在pipeline中写3个机器。默认replace-datanode-on-failure.policy是DEFAULT,如果系统中的datanode大于等于3,它会找另外一个datanode来拷贝。目前机器只有3台,因此只要一台datanode出问题,就一直无法写入成功。
解决办法:修改hdfs-site.xml文件,添加或者修改如下两项:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<property> <!-- 客户端在写失败的时候,是否使用更换策略,默认是true没有问题 --> <name>dfs.client.block.write.replace-datanode-on-failure.enable</name> <value>true</value> </property>) <property> <!-- default在3个或以上备份的时候,是会尝试更换结点尝试写入datanode。而在两个备份的时候,不更换datanode,直接开始写。对于3个datanode的集群,只要一个节点没响应写入就会出问题,所以可以关掉 --> <name>dfs.client.block.write.replace-datanode-on-failure.policy</name> <value>NEVER</value> </property> <!-- 还有个 --> <property> <!-- 追加写入的功能,但不建议在生产环境中使用,原因如下:Does HDFS allow appends to files? This is currently set to false because there are bugs in the "append code" and is not supported in any prodction cluster. --> <name>dfs.support.append</name> <value>true</value> </property> |
修改xml文件的做法只对shell起作用,在eclipse中的代码还得用conf.set("","");
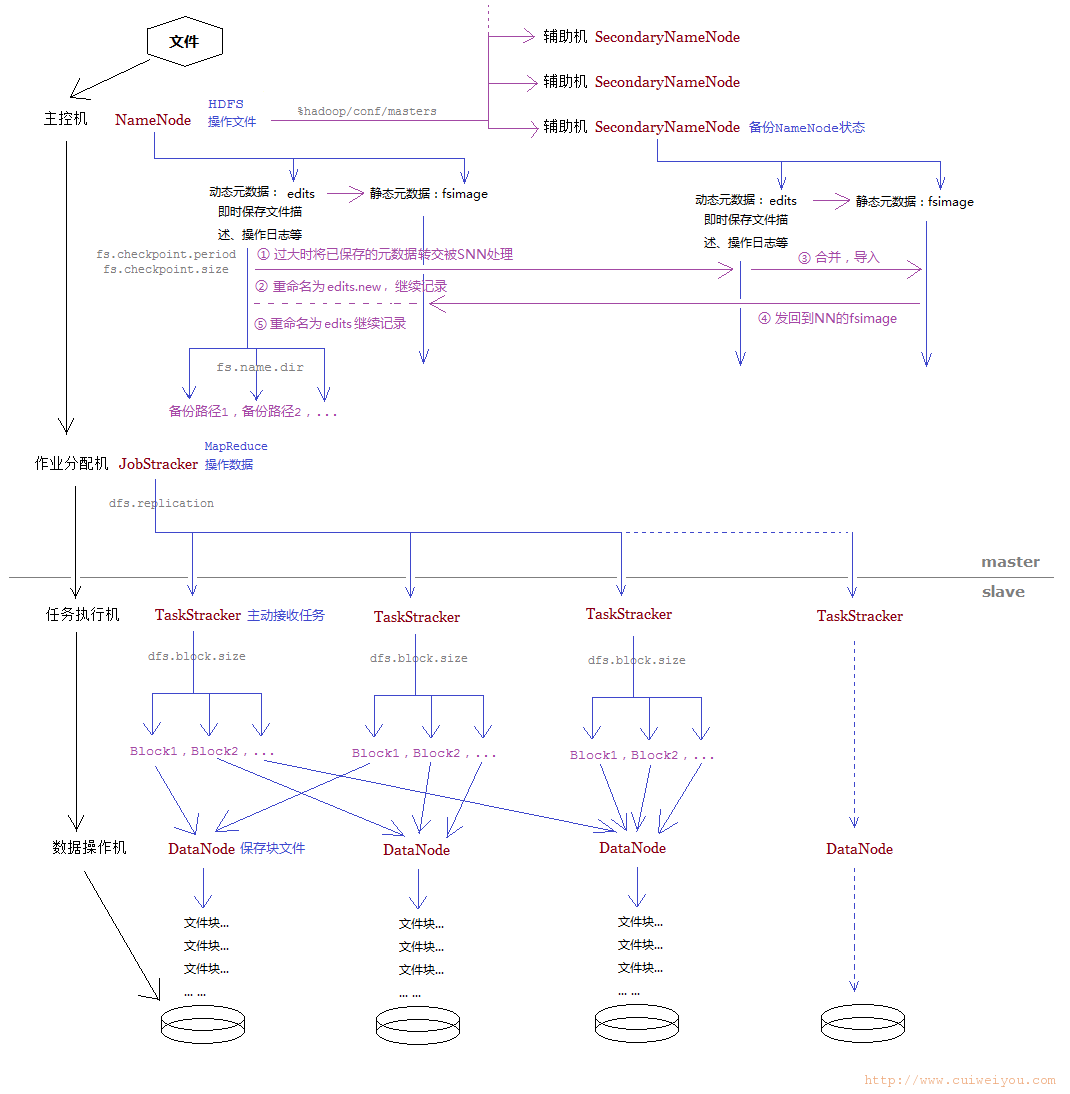
3.HDFS运行流程参考图
本文由崔维友 威格灵 cuiweiyou vigiles cuiweiyou 原创,转载请注明出处:http://www.gaohaiyan.com/1405.html
承接App定制、企业web站点、办公系统软件 设计开发,外包项目,毕设



