本文hadoop2.7.0

首先提供一个jar反编译器,挺好用
[download id="1421"]从%hadoop-2.7.0%\share\hadoop\mapreduce中找到hadoop-mapreduce-examples-2.7.0.jar
用jar反编译器打开即可查看/复制/保存其中的WordCount源码
注意本文代码不能通过@Test注解的方式运行。
1.WordCount
源数据,每个单词直接用空格隔开,可以写多行。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
package com.cuiweiyou.test; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; // 注意这两个类的路径,和之前版本不同 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; //import org.apache.hadoop.mapred.FileInputFormat; // 如果使用这两个类,要求JobConf //import org.apache.hadoop.mapred.FileOutputFormat; public class WordCount { /** * 先经过mapper运算,然后才是reducer。 * 内部类:映射器 Mapper<Key_IN, Value_IN, Key_OUT, Value_OUT> * 首先读取源文本 */ public static class MyMapper extends Mapper<Object, Text, Text, IntWritable> { //占位体,1,查到一个就占个坑 private static final IntWritable one = new IntWritable(1); //文本 private Text word = new Text(); /** * 重写map方法,实现理想效果 * MyMapper的实例只有一个,但实例的这个map方法却一直在执行,直到读取结束 * Key1:本行首字符在全文中的索引。Value1:本行的文本。context:上下文对象,在整个wordcount运算生命周期内存活 * 这里K1、V1像这样[K,V] **/ public void map(Object key1, Text value1, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { //拆分字符串,返回单词集合。默认以空格和换行/回车拆分 StringTokenizer itr = new StringTokenizer(value1.toString()); //遍历一行的全部单词 while (itr.hasMoreTokens()) { //将文本转为临时Text变量 this.word.set(itr.nextToken()); //将单词保存到上下文对象中(单词,占位体),输出 context.write(this.word, one); } } } /************************************************************************ * 在Mapper后,Reducer前,有个shuffle过程,会根据k2将对应的v2归并为v2[...] * * www.cuiweiyou.com *************************************************************************/ /** * mapper结束后,执行现在的reducer。 * 内部类:拆分器 Reducer<Key_IN, Value_IN, Key_OUT, Value_OUT> */ public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { //计数器。个数统计 private IntWritable result = new IntWritable(); /** * 重写reduce方法,实现理想效果 * MyReducer的实例也只有一个,但实例的这个reduce方法却一直在执行,直到完成统计 * Key2:单词。Values2:value的集合,也就是[1,1,1,...]。context:上下文对象 * 这里这里K2、V2像这样[K,V[1,1,1,...]]。每执行一次,key就是一个新单词,对应的values就是其全部占位体 **/ public void reduce(Text key2, Iterable<IntWritable> values2, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; //累加V2的元素,有多少个 占位体1 ,即有多少个指定单词 for (IntWritable val : values2) { sum += val.get(); } this.result.set(sum); //终于将单词和总个数再次输出 context.write(key2, this.result); // 输出到 hdfs:/output 中到结果文件 } } public static void main(String[] args) throws Exception { // HDFS配置 Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); // 作业(环境,作业名) Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); // 执行作业的类 job.setMapperClass(MyMapper.class); // 读取源数据,执行map运算的类 /* Combiner * 通常,每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量。 * combiner的输入输出类型必须和mapper的输出以及reducer的输入类型一致 */ job.setCombinerClass(MyReducer.class); // 统计数据,执行reduce的类 job.setReducerClass(MyReducer.class); // 统计数据,执行reduce的类 job.setOutputKeyClass(Text.class); // 设置输出的key类型,和Context上下文对象write的参数类型一致 job.setOutputValueClass(IntWritable.class); // 设置输出的value类型 FileInputFormat.addInputPath(job, new Path("hdfs:/input")); // 源数据路径,须已存在 FileOutputFormat.setOutputPath(job, new Path("hdfs:/output")); // 统计结果输出路径,须程序自动创建 // 等待提交作业到集群并完成,才结束程序 System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
然后可以结合HDFS的javaapi写程序查看。或者直接shell。
2.Sort
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
package com.cuiweiyou.test; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; //hadoop默认排序: //如果k2、v2类型是Text-文本,结果是按照字典顺序 //如果k2、v2类型是LongWritable-数字,结果是按照数字大小顺序 public class Sort { /** * 内部类:映射器 Mapper<KEY_IN, VALUE_IN, KEY_OUT, VALUE_OUT> * 读数据 */ public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, NullWritable> { /** * 重写map方法 * 每行一个数字,每次读一行 */ public void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException { //k1是行号,无用,舍弃k1 // 这里文本v1转为数字k2。null为新的v2 context.write(new LongWritable(Long.parseLong(v1.toString())), NullWritable.get()); // 新的k2可能有重复,但没有保存对应的占位体 } } /*** 在此方法执行前,有个shuffle过程,会根据k2将对应的v2归并为v2[...] ***/ /** * 内部类:拆分器 Reducer<KEY_IN, VALUE_IN, KEY_OUT, VALUE_OUT> */ public static class MyReducer extends Reducer<LongWritable, NullWritable, LongWritable, NullWritable> { /** * 重写reduce方法 */ protected void reduce(LongWritable k2, Iterable<NullWritable> v2, Context context) throws IOException, InterruptedException { //数字k2转为结果k3, v2[...]舍弃 context.write(k2, NullWritable.get()); //此时,k3如果发生重复,根据默认算法会发生覆盖,即最终仅保存一个k3 } } public static void main(String[] args) throws Exception { // HDFS配置 Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); // 作业(环境,作业名) Job job = Job.getInstance(conf, "SortTest"); job.setJarByClass(Sort.class); // 执行作业的类 job.setMapperClass(MyMapper.class); // 读取源数据,执行map运算的类 job.setCombinerClass(MyReducer.class); // 统计数据,执行reduce的类 job.setReducerClass(MyReducer.class); // 统计数据,执行reduce的类 job.setOutputKeyClass(LongWritable.class); // 设置输出的key类型,和Context上下文对象write的参数类型一致 job.setOutputValueClass(NullWritable.class); // 设置输出的value类型 FileInputFormat.addInputPath(job, new Path("hdfs:/input")); // 源数据路径,须已存在 FileOutputFormat.setOutputPath(job, new Path("hdfs:/output")); // 统计结果输出路径,须程序自动创建 // 等待提交作业到集群并完成,才结束程序 System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
3.去重
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
关键代码 /* * 内部类:映射器 Mapper<KEY_IN, VALUE_IN, KEY_OUT, VALUE_OUT> */ public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, NullWritable> { /**** * 重写map方法 ****/ public void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException { //因为我们读入的数据就是一行一个数字,直接使用 //这个数字有几个都无所谓,只有知道有这么一个数字即可,所以输出的v2为null context.write(new LongWritable(Long.parseLong(v1.toString())), NullWritable.get()); } } /** 在此方法执行前,有个shuffle过程,会根据k2将对应的v2归并为v2[...] **/ /* * 内部类:拆分器 Reducer<KEY_IN, VALUE_IN, KEY_OUT, VALUE_OUT> */ public static class MyReducer extends Reducer<LongWritable, NullWritable, LongWritable, NullWritable> { /**** * 重写reduce方法 ****/ protected void reduce(LongWritable k2, Iterable<NullWritable> v2, Context context) throws IOException, InterruptedException { //此时,k3(即眼前的k2)如果发生重复,根据默认算法会发生覆盖,即最终仅保存一个k3,达到去重到效果,而v3是null无所谓 context.write(k2, NullWritable.get()); } } |
4.过滤
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
关键代码 /* * 内部类:映射器 Mapper<KEY_IN, VALUE_IN, KEY_OUT, VALUE_OUT> */ public static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> { String tmp = "8238"; /** * 重写map方法。k1:行首字符索引,v1:这一行文本 **/ protected void map(LongWritable k1, Text v1, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException ,InterruptedException { System.out.println(v1+", "+tmp); //如果行文本是指定值,过滤之 if(v1.toString().equals(tmp)){ System.out.println("有了"); //保存(按照泛型限制,k2是Text,v2是Nullritable) context.write(v1, NullWritable.get()); } } } /* * 内部类:拆分器 Reducer<KEY_IN, VALUE_IN, KEY_OUT, VALUE_OUT> */ public static class MyReducer extends Reducer<Text, NullWritable, Text, NullWritable> { /** * 重写reduce方法 **/ protected void reduce(Text k2, Iterable<NullWritable> v2, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException ,InterruptedException { context.write(k2, NullWritable.get()); } } |
5.最大值
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
关键代码 // map(泛型定义了输入和输出类型) public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, NullWritable> { // 首先创建一个临时变量,保存一个可存储的最小值:Long.MIN_VALUE=-9223372036854775808 long temp = Long.MIN_VALUE; // 找出最大值。这个map不断迭代v1,最终保存最大值 protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException { // 将文本转数值 long val = Long.parseLong(v1.toString()); // 如果v1比临时变量大,则保存v1的值 if (temp < val) { temp = val; } } /** ---此方法在全部的map任务结束后执行一次。这时仅输出临时变量到最大值--- **/ protected void cleanup(Context context) throws IOException, InterruptedException { context.write(new LongWritable(temp), NullWritable.get()); System.out.println("文件读取完毕,保存最大值"); //输出两次,对应两个文本文件 } } // reduce public static class MyReducer extends Reducer<LongWritable, NullWritable, LongWritable, NullWritable> { // 临时变量 Long temp = Long.MIN_VALUE; // 因为一个文件得到一个最大值,我们有两个txt文件会得到两个值。再次将这些值比对,得到最大的 protected void reduce(LongWritable k2, Iterable<NullWritable> v2, Context context) throws IOException, InterruptedException { long val = Long.parseLong(k2.toString()); // 如果k2比临时变量大,则保存k2的值 if (temp < val) { temp = val; } } /** !!!此方法在全部的reduce任务结束后执行一次。这时仅输出唯一最大值!!! **/ protected void cleanup(Context context) throws IOException, InterruptedException { context.write(new LongWritable(temp), NullWritable.get()); } } |
6. 前5最大值
本例有两个txt文件。注意每行一个数字,无空格/空行。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
// map public static class MyMapper extends Mapper<LongWritable, Text, LongWritable, NullWritable> { public MyMapper() { System.err.println("MyMapper实例化......"); } // 首先创建一个临时变量,保存一个可存储的最小值:Long.MIN_VALUE=-9223372036854775808 long temp = Long.MIN_VALUE; // Top5存储空间,我们取前5个 long[] tops; /** 这个方法在run中调用,在全部map之前执行一次 **/ protected void setup(Context context) { // 初始化数组长度为5 tops = new long[5]; System.err.println("Mapper-setup执行。。。"); } // 找出最大值 public void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException { // 将文本转数值 final long val = Long.parseLong(v1.toString()); System.err.println("map读到:" + val); // 保存在0索引 if(val > tops[0]) tops[0] = val; // 排序后最大值在最后一个索引,这样从[5]到[0]依次减小。每执行一次map,最小的[0]都会赋予新值 Arrays.sort(tops); System.err.println("map ing ---" + Arrays.toString(tops)); } /** ---此方法在全部的map任务结束后执行一次。输出map后得到的前5个最大值--- **/ protected void cleanup(Context context) throws IOException, InterruptedException { for (int i = 0; i < tops.length; i++) { context.write(new LongWritable(tops[i]), NullWritable.get()); } System.err.println("Mapper-cleanup处理。。。"); } } // reduce public static class MyReducer extends Reducer<LongWritable, NullWritable, LongWritable, NullWritable> { public MyReducer() { System.err.println("MyReduce instance ..."); } Long temp = Long.MIN_VALUE; long[] tops; /** 次方法在run中调用,在全部map之前执行一次 **/ protected void setup(Context context) { tops = new long[5]; System.err.println("MyReduce-setup..."); } // 因为每个文件都得到5个值,再次将这些值比对,得到最大的 protected void reduce(LongWritable k2, Iterable<NullWritable> v2, Context context) throws IOException, InterruptedException { long top = Long.parseLong(k2.toString()); System.err.println("reduce读到:" + top); if (top>tops[0]) tops[0] = top; Arrays.sort(tops); System.err.println("reduce ing ---" + Arrays.toString(tops)); } /** ---此方法在全部到reduce任务结束后执行一次--- **/ protected void cleanup(Context context) throws IOException, InterruptedException { for (int i = 0; i < tops.length; i++) { context.write(new LongWritable(tops[i]), NullWritable.get()); } System.err.println("MyReduce-cleanup..."); } } |
相关日志:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
# 第一次 map,第一个txt文件 MyMapper实例化...... Mapper-setup执行。。。 map读到:8764 map ing ---[0, 0, 0, 0, 8764] map读到:7367 map ing ---[0, 0, 0, 7367, 8764] map读到:3498 map ing ---[0, 0, 3498, 7367, 8764] map读到:483275 map ing ---[0, 3498, 7367, 8764, 483275] map读到:632300 map ing ---[3498, 7367, 8764, 483275, 632300] map读到:3450 map ing ---[3498, 7367, 8764, 483275, 632300] map读到:10 map ing ---[3498, 7367, 8764, 483275, 632300] map读到:4 map ing ---[3498, 7367, 8764, 483275, 632300] map读到:8 map ing ---[3498, 7367, 8764, 483275, 632300] map读到:33 map ing ---[3498, 7367, 8764, 483275, 632300] map读到:5 map ing ---[3498, 7367, 8764, 483275, 632300] map读到:8 map ing ---[3498, 7367, 8764, 483275, 632300] map读到:6 map ing ---[3498, 7367, 8764, 483275, 632300] map读到:45 map ing ---[3498, 7367, 8764, 483275, 632300] Mapper-cleanup处理。。。 # 第一次 reduce,第一个txt文件map后的结果 MyReduce instance ... MyReduce-setup... reduce读到:3498 reduce ing ---[0, 0, 0, 0, 3498] reduce读到:7367 reduce ing ---[0, 0, 0, 3498, 7367] reduce读到:8764 reduce ing ---[0, 0, 3498, 7367, 8764] reduce读到:483275 reduce ing ---[0, 3498, 7367, 8764, 483275] reduce读到:632300 reduce ing ---[3498, 7367, 8764, 483275, 632300] MyReduce-cleanup... # 第二次 map,第二个txt文件 MyMapper实例化...... Mapper-setup执行。。。 map读到:8764 map ing ---[0, 0, 0, 0, 8764] map读到:7367 map ing ---[0, 0, 0, 7367, 8764] map读到:3498 map ing ---[0, 0, 3498, 7367, 8764] map读到:483275 map ing ---[0, 3498, 7367, 8764, 483275] map读到:6323 map ing ---[3498, 6323, 7367, 8764, 483275] map读到:3450 map ing ---[3498, 6323, 7367, 8764, 483275] map读到:10 map ing ---[3498, 6323, 7367, 8764, 483275] map读到:4 map ing ---[3498, 6323, 7367, 8764, 483275] map读到:8 map ing ---[3498, 6323, 7367, 8764, 483275] map读到:33 map ing ---[3498, 6323, 7367, 8764, 483275] map读到:5 map ing ---[3498, 6323, 7367, 8764, 483275] map读到:8 map ing ---[3498, 6323, 7367, 8764, 483275] map读到:6 map ing ---[3498, 6323, 7367, 8764, 483275] map读到:45 map ing ---[3498, 6323, 7367, 8764, 483275] Mapper-cleanup处理。。。 # 第二次 reduce,第二个txt文件map后的结果 MyReduce instance ... MyReduce-setup... reduce读到:3498 reduce ing ---[0, 0, 0, 0, 3498] reduce读到:6323 reduce ing ---[0, 0, 0, 3498, 6323] reduce读到:7367 reduce ing ---[0, 0, 3498, 6323, 7367] reduce读到:8764 reduce ing ---[0, 3498, 6323, 7367, 8764] reduce读到:483275 reduce ing ---[3498, 6323, 7367, 8764, 483275] MyReduce-cleanup... # 第三次 reduce,两次map运算txt文件的结果 MyReduce instance ... MyReduce-setup... reduce读到:3498 reduce ing ---[0, 0, 0, 0, 3498] reduce读到:6323 reduce ing ---[0, 0, 0, 3498, 6323] reduce读到:7367 reduce ing ---[0, 0, 3498, 6323, 7367] reduce读到:8764 reduce ing ---[0, 3498, 6323, 7367, 8764] reduce读到:483275 reduce ing ---[3498, 6323, 7367, 8764, 483275] reduce读到:632300 reduce ing ---[6323, 7367, 8764, 483275, 632300] MyReduce-cleanup... |
7.数量最大
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
public static class MyMapper extends Mapper<Object, Text, Text, IntWritable> { private static final IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object Key1, Text Value1, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { String[] strings = Value1.toString().split(" "); for (String str : strings) { this.word.set(str); context.write(this.word, one); } } } public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { //临时变量,保存最大数量的单词 private String keyer; //注意这里不能用Hadoop的类型,如Text private IntWritable valer; //这里最好也是基本的java数据类型,如int //计数 private Integer temp = Integer.MIN_VALUE; public void reduce(Text Key2, Iterable<IntWritable> Values2, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; //统计数量 for (IntWritable val : Values2) { sum += val.get(); } //保存最大数量值 if (sum > temp) { temp = sum; keyer = Key2.toString(); valer = new IntWritable(temp); } } //最终输出最大数量的单词 protected void cleanup(Context context) throws IOException, InterruptedException { context.write(new Text(keyer), valer); } } |
8.单表关联
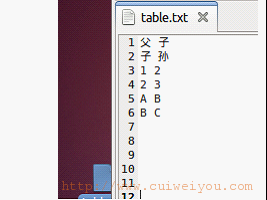
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
/* 父 子 子 孙 2 3 A B B C */ // map public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> { // 拆分原始数据 protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException { // 按制表符拆分记录。一行拆出两个角色 String[] splits = v1.toString().split(" "); //针对无意义的换行过滤 if (splits.length > 1) { // 把“父”作为k2;“子“加下划线区分,作为v2 context.write(new Text(splits[0]), new Text("_" + splits[1])); // 把“子”作为k2;“父”辈作为v2。就是把原两个单词调换位置保存 context.write(new Text(splits[1]), new Text(splits[0])); } } /** * 父 _子 * 子 父 * * 子 _孙 * 孙 子 **/ } /** * k2 v2[...] * 子 [父,_孙] **/ // reduce public static class MyReducer extends Reducer<Text, Text, Text, Text> { // 拆分k2v2[...]数据 protected void reduce(Text k2, Iterable<Text> v2, Context context) throws IOException, InterruptedException { String grandson = ""; // “孙” String grandfather = ""; // “父” // 从迭代中遍历v2[...] for (Text man : v2) { String p = man.toString(); System.out.println("得到:" + p); // 如果单词是以下划线开始的 if (p.startsWith("_")) { grandson = p.substring(1); } // 如果单词没有下划线起始 else { // 直接赋值给孙辈变量 grandfather = p; } } // 在得到有效数据的情况下 if (grandson != "" && grandfather != "") { // 写出得到的结果。 context.write(new Text(grandson), new Text(grandfather)); } /** * k3=父,v3=孙 **/ } } |
9.双表关联

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
// map public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> { // 拆分原始数据 protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException { // 拆分记录 String[] splited = v1.toString().split(" "); // 如果第一列是数字(使用正则判断),就是歌曲表。先读入那个文件由hadoop决定 if (splited[0].matches("^[-+]?(([0-9]+)([.]([0-9]+))?|([.]([0-9]+))?)$")) { String id = splited[0]; String song = splited[1]; //v2加两条下划线作为前缀标识为歌曲 context.write(new Text(id), new Text("__" + song)); } // 否则就是歌手表 else { String singer = splited[0]; String id = splited[1]; //v2-加两条横线作为前缀标识为歌手 context.write(new Text(id), new Text("--" + singer)); } /** * 1 __Eminem 1 --LoseYourself **/ } } // reduce public static class MyReducer extends Reducer<Text, Text, Text, Text> { // 拆分k2v2[...]数据 protected void reduce(Text k2, Iterable<Text> v2, Context context) throws IOException, InterruptedException { String song = ""; // 歌曲 String singer = ""; // 歌手 /** * 1, [__Eminem, --LoseYourself] **/ for (Text text : v2) { String tmp = text.toString(); if (tmp.startsWith("__")) { // 如果是__开头的是song song = tmp.substring(2); // 从索引2开始截取字符串 } if (tmp.startsWith("--")) { // 如果是--开头的是歌手 singer = tmp.substring(2); } } context.write(new Text(singer), new Text(song)); } /** * k3=Eminem,v3=LoseYourself * Eminem LoseYourself Alizee LaIslaBonita Michael YouAreNotAlone Manson FuckFrankie * **/ } |
这些内容曾发布在:
http://my.oschina.net/vigiles/blog/151138
http://www.cnblogs.com/vigiles/p/3623621.html
注意版本不同。
10.MapReduce参考流程图
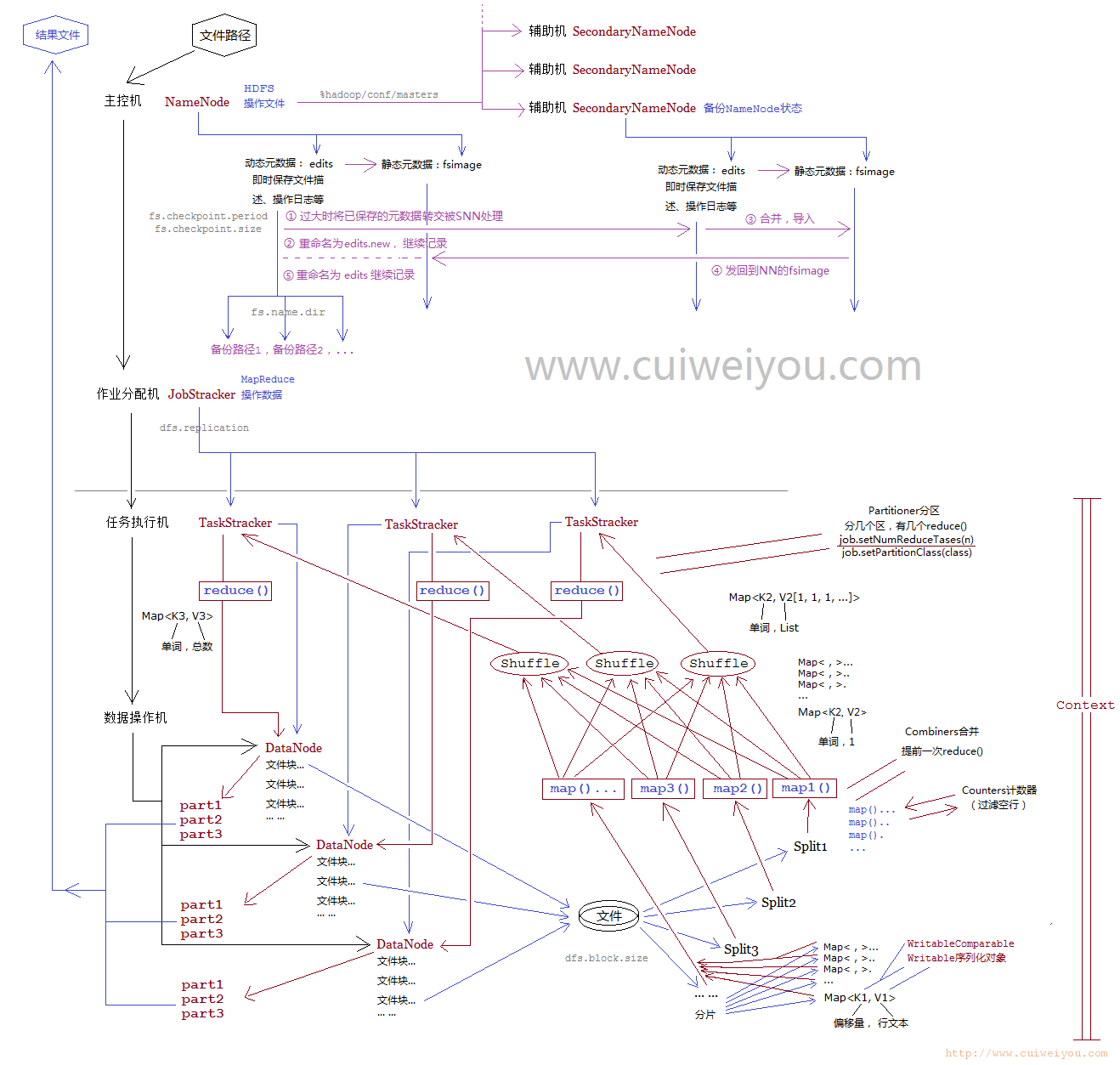
例题
问:已知一个单身美女的坐标,和一群单身帅哥的坐标,求离美女最近的帅哥。
答:数学中有公式Math.sqrt(Math.abs(x-x2)*Math.abs(x-x2)+Math.abs(y-y2)*Math.abs(y-y2))可以求出两点的距离。
在Mapper中map遍历帅哥的坐标,就能得到每个帅哥和美女的距离。
将距离作为key、坐标作为value存入context。
MR运算,map执行结束后的shuffle过程,可以去除重复的key,并保存key对应的value,这样即使有多个帅哥和美女的距离相同也能保存下来;同时这个shuffle按照默认算法进行排序,数字按大小,字符按字典顺序。
所以到了Reduce时,已经是我们想要的结果,最上面的最小key就是最近距离。
其实是排序算法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
package com.cuiweiyou.test; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class HadoopTest { public static class MyMapper extends Mapper<LongWritable, Text, DoubleWritable, Text>{ int x1 = 32; // 美女坐标x int y1 = 2; // 美女坐标y /** 遍历坐标数据。每行数据对应一个map方法 * 这里k1=读入行的首字符索引,v1=坐标数据,k2=输出行号也就是对比过的坐标索引,v2=输出的距离值 **/ public void map(LongWritable key, Text value, Context context) throws IOException ,InterruptedException { String[] points = value.toString().split(" "); // 读入坐标数据 int x2 = Integer.valueOf(points[0]); int y2 = Integer.valueOf(points[1]); // 计算距离 double sqrt = Math.sqrt(Math.abs(x1-x2)*Math.abs(x1-x2)+Math.abs(y1-y2)*Math.abs(y1-y2)); // 保存全部距离 context.write(new DoubleWritable(sqrt), value); }; } /** 按照MR的默认算法,此时已经把Key按照数字大小做了排序 **/ public static class MyReducer extends Reducer<DoubleWritable, Text, DoubleWritable, Text> { String points = ""; /** 遍历全部文件的坐标数据比对结果 * 每次读一条结果,value是距离值 **/ public void reduce(DoubleWritable key, Iterable<Text> value, Context context) throws IOException ,InterruptedException { for(Text txt : value){ String[] ps = txt.toString().split(" "); points += "x:" + ps[0] + ",y:" + ps[1]; } context.write(key, new Text(points)); points = ""; } } public static void main(String[] args) throws Exception, InterruptedException { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://localhost:9000"); Job job = Job.getInstance(conf, "Point"); job.setJarByClass(HadoopTest.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(DoubleWritable.class); // 注意匹配 job.setOutputValueClass(Text.class); // 注意匹配 FileInputFormat.addInputPath(job, new Path("hdfs:/input/")); FileOutputFormat.setOutputPath(job, new Path("hdfs:/output/")); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
如果遇到执行中map或者reduce方法不执行且eclipse不报错的情况,多是因为job.setOutputKeyClass或FileOutputFormat.setOutputPath设置的输出类型不对,还有自定义Mapper/Reducer中泛型和context写出不匹配。
本例源数据(空格分开x、y坐标):
12 10
23 23
20 20
1 3
23 7
输出(第一行即是最近的):
10.295630140987 x:23,y:7
21.540659228538015 x:12,y:10
21.633307652783937 x:20,y:20
22.847319317591726 x:23,y:23
31.016124838541646 x:1,y:3
本文由崔维友 威格灵 cuiweiyou vigiles cuiweiyou 原创,转载请注明出处:http://www.gaohaiyan.com/1420.html
承接App定制、企业web站点、办公系统软件 设计开发,外包项目,毕设



