Hadoop环境准备参考 www.cuiweiyou.com/1399.html
apache全部下载 http://www.apache.org/dyn/closer.cgi/
奇数版本号为“开发人员预览版” (developer previews),偶数版本号为可以产品化的“稳定版”(stable)
http://www.apache.org/dyn/closer.cgi/hbase/
一。安装HBase1.0.1
1.下载解压
选择合适目录 如 /home/
配置环境变量,/etc/bashrc文件、/etc/profile文件(一般选这个)、~/.bash_profile文件、~/.bashrc文件(本例)。
export HBASE_HOME=/home/hbase-1.0.1
export PATH=$HBASE_HOME/bin:$PATH
|
1 2 3 4 5 6 |
root@debian:/# source ~/.bashrc root@debian:/# hbase version 2015-05-12 11:16:21,159 INFO [main] util.VersionInfo: HBase 1.0.1 2015-05-12 11:16:21,161 INFO [main] util.VersionInfo: Source code repository git://...git-repos/hbase revision=66a93c |
2.编辑hbase_env.sh
文件路径 /home/hbase-1.0.1/conf/hbase-env.sh
|
1 2 3 4 5 6 |
export JAVA_HOME=/usr/share/jdk1.7.0_80 #约29行,JDK路径 export HBASE_CLASSPATH=/home/hadoop-2.7.0/etc/hadoop #约32行,hadoop 的配置文件路径 export HBASE_PID_DIR=/home/hbase-1.0.1/hbase_pids #约118行,已存在不易丢失文件的pid存放目录 export HBASE_MANAGES_ZK=true #约126行,true(默认)指hbase使用内置Zookeeper,false则使用另外单独安装的 |
3.修改hbase-site.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <!-- 指定本机hbase的存储目录。主机和端口号与hadoop的core-site.xml中fs.defaultFS一致 --> <name>hbase.rootdir</name> <value>hdfs://localhost:9000/hbase-1.0.1/hbase_data</value> <!-- 下面是单机模式配法 --> <!-- value>file:/home/hbase1.0.1/hbase_data</value --> </property> <property> <!-- 指定hbase的master主机名和端口。配置多台master时只需要提供端口,因为选择master由zookeeper执行 --> <name>hbase.master</name> <!-- name>hbase.master.port</name --> <!-- value>60000</value --> <value>hdfs://localhost:60000</value> </property> <property> <!-- 指定Master web 界面端口 --> <name>hbase.master.info.port</name> <value>60010</value> <!-- 默认即是 --> </property> <property> <!-- 指定hbase的临时目录 --> <name>hbase.tmp.dir</name> <value>/home/hbase-1.0.1/hbase_tmp</value> </property> <property> <!-- 指定hbase运行模式,true代表全分布模式,多节点间的hbase会互通。伪分布式也是分布式 --> <name>hbase.cluster.distributed</name> <value>true</value> <!-- 单机模式配法 --> <!-- value>false</value --> </property> <property> <!-- 指定Zookeeper所在主机节点,须使用奇数个确保选举leader公平 --> <name>hbase.zookeeper.quorum</name> <!-- 这里配主机名,多个主机名使用英文逗号隔开。本例在hadoop伪分布式中 --> <value>localhost</value> </property> <property> <!-- 指定Zookeeper数据存放位置 --> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hbase-1.0.1/zookeeper_data</value> </property> </configuration> |
4.配置regionservers
|
1 2 3 |
localhost #和hadoop的slaves文件中一致 |
5.替换jar
进入 hbase 的 lib 目录,查看 hadoop jar 包的版本
可以使用命令:find -name 'hadoop*jar'
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
./hadoop-annotations-2.5.1.jar ./hadoop-auth-2.5.1.jar ./hadoop-client-2.5.1.jar ./hadoop-common-2.5.1.jar ./hadoop-hdfs-2.5.1.jar ./hadoop-mapreduce-client-app-2.5.1.jar ./hadoop-mapreduce-client-common-2.5.1.jar ./hadoop-mapreduce-client-core-2.5.1.jar ./hadoop-mapreduce-client-jobclient-2.5.1.jar ./hadoop-mapreduce-client-shuffle-2.5.1.jar ./hadoop-yarn-api-2.5.1.jar ./hadoop-yarn-client-2.5.1.jar ./hadoop-yarn-common-2.5.1.jar ./hadoop-yarn-server-common-2.5.1.jar ./hadoop-yarn-server-nodemanager-2.5.1.jar |
可见当前hbase-1.0.1对应的hadoop版本为2.5.1,而当前安装的hadoop集群使用2.7.0版本。
需要用%hadoop%/share/hadoop/目录下的对应名称jar来替换。
hadoop-client-*.jar可在这里找到http://maven.outofmemory.cn/org.apache.hadoop/hadoop-client/
6.同步全部主机
如果是分布式集群,须将hbase目录拷贝到其它主机同目录下,同时修改其它主机的环境变量,使全部主机配置相同。
7.启动hbase
首先启动HDFS系统
然后启动HBase
start-hbase.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
root@debian:~# start-dfs.sh Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop-2.7.0/logs/hadoop-root-namenode-debian.out localhost: starting datanode, logging to /home/hadoop-2.7.0/logs/hadoop-root-datanode-debian.out Starting secondary namenodes [localhost] localhost: starting secondarynamenode, logging to /home/hadoop-2.7.0/logs/hadoop-root-secondarynamenode-debian.out root@debian:~# start-hbase.sh localhost: starting zookeeper, logging to /home/hbase-1.0.1/logs/hbase-root-zookeeper-debian.out starting master, logging to /home/hbase-1.0.1/logs/hbase-root-master-debian.out starting regionserver, logging to /home/hbase-1.0.1/logs/hbase-root-1-regionserver-debian.out root@debian:~# jps 2099 DataNode 2763 HRegionServer # regionservers中配置的节点有此进程 2870 Jps 2677 HMaster # hbase.master配置的主机才有此进程 2005 NameNode 2237 SecondaryNameNode 2590 HQuorumPeer # hbase.zookeeper.quorum中配置了的主机才有此进程 root@debian:~# root@debian:~# stop-hbase.sh # 停止HBase root@debian:~# |
web管理页面地址:
HMaster地址 http://localhost:60010/master-status
HRegionServer地址 http://localhost:16301/rs-status
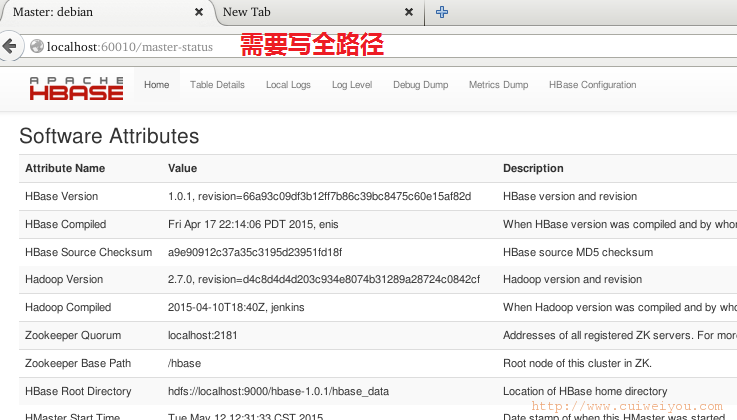
查看日志发现有3个问题
hbase-root-zookeeper-debian.log 文件头部。这个估计是因为当前集群在伪分布式中,且仅配了一个zookeeper服务器。
ERROR [main] quorum.QuorumPeerConfig: Invalid configuration, only one server specified (ignoring)
hbase-root-master-debian.log文件
WARN [debian:16020.activeMasterManager] zookeeper.ZKTableStateManager: Moving table hbase:meta state from null to ENABLED
WARN [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181] server.NIOServerCnxn: caught end of stream exception
EndOfStreamException: Unable to read additional data from client sessionid 0x14d4631029e0003, likely client has closed socket
尚未处理。
hbase-root-master-debian.log文件:
这个错误很操蛋,在start-hbase.sh后出现,jps只能看到dfs的3个进程和HQuorumPeer进程。没有HRegionServer和HMaster。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
ERROR org.apache.hadoop.hbase.master.HMasterCommandLine: Failed to start master
java.lang.RuntimeException: Failed construction of Master: class org.apache.hadoop.hbase.master.HMaster
at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:2106)
at org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:152)
at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:104)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:65)
at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:76)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:2120)
Caused by: java.net.BindException: 无法指定被请求的地址 #毛意思?
at sun.nio.ch.Net.bind0(Native Method)
at sun.nio.ch.Net.bind(Net.java:444)
at sun.nio.ch.Net.bind(Net.java:436)
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:214)
at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74)
at org.apache.hadoop.hbase.ipc.HBaseServer.bind(HBaseServer.java:256)
at org.apache.hadoop.hbase.ipc.HBaseServer$Listener.
at org.apache.hadoop.hbase.ipc.HBaseServer.
at org.apache.hadoop.hbase.ipc.WritableRpcEngine$Server.
at org.apache.hadoop.hbase.ipc.WritableRpcEngine.getServer(WritableRpcEngine.java:204)
at org.apache.hadoop.hbase.ipc.WritableRpcEngine.getServer(WritableRpcEngine.java:56)
at org.apache.hadoop.hbase.ipc.HBaseRPC.getServer(HBaseRPC.java:330)
at org.apache.hadoop.hbase.ipc.HBaseRPC.getServer(HBaseRPC.java:319)
at org.apache.hadoop.hbase.master.HMaster.
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:2101)
... 5 more
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
一点亮眼的提示也没有啊。拜读良久,修改 /etc/hosts 文件:
127.0.0.1 localhost debian
只保留这一句,127.0.0.1回路IP,对应localhost和主机名。
二。常用的HBase Shell
在HBASE_HOME中创建一个a.txt文件,执行shell时使用
root@debian:~# hbase shell a.txt
可以将执行的shell命令都保存起来。但本例不能保存,文件一直为空。可能是版本的问题。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
root@debian:~# hbase shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/home/hbase-1.0.1/lib/slf4j-log4j12-1.7.7.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/home/hadoop-2.7.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 1.0.1, r66a93c09df3b12ff7b86c39bc8475c60e15af82d, Fri Apr 17 22:14:06 PDT 2015 hbase(main):001:0> |
这个问题是因为Hadoop目录lib中jar包slf4j-log4j和HBase目录中的重复,将HBase目录中的删除。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
hbase(main):031:0> help HBase Shell, version 1.0.1, r66a93c09df3b12ff7b86c39bc8475c60e15af82d, Fri Apr 17 22:14:06 PDT 2015 Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command. Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group. COMMAND GROUPS: Group name: 关于表的全局命令general Commands: status, table_help, version, whoami Group name: 数据库模式定义语言DDL命令ddl Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, show_filters Group name: 命名空间命令namespace Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables Group name: 数据操纵语言DML命令dml Commands: append, count, delete, deleteall, get, get_counter, incr, put, scan, truncate, truncate_preserve Group name: 工具类命令tools Commands: assign, balance_switch, balancer, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, close_region, compact, compact_rs, flush, major_compact, merge_region, move, split, trace, unassign, wal_roll, zk_dump Group name: 备份操作命令replication Commands: add_peer, append_peer_tableCFs, disable_peer, enable_peer, list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCFs Group name: 快照操作命令snapshots Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, list_snapshots, restore_snapshot, snapshot Group name: 配置信息操作命令configuration Commands: update_all_config, update_config Group name: 权限操作命令security Commands: grant, revoke, user_permission Group name: 可见性标签操作命令visibility labels Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility SHELL USAGE: Quote all names in HBase Shell such as table and column names. Commas delimit command parameters. Type <RETURN> after entering a command to run it. Dictionaries of configuration used in the creation and alteration of tables are Ruby Hashes. They look like this: {'key1' => 'value1', 'key2' => 'value2', ...} and are opened and closed with curley-braces. Key/values are delimited by the '=>' character combination. Usually keys are predefined constants such as NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type 'Object.constants' to see a (messy) list of all constants in the environment. If you are using binary keys or values and need to enter them in the shell, use double-quote'd hexadecimal representation. For example: hbase> get 't1', "key\x03\x3f\xcd" hbase> get 't1', "key\003\023\011" hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40" The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added. For more on the HBase Shell, see http://hbase.apache.org/book.html hbase(main):032:0> |
常用shell命令:
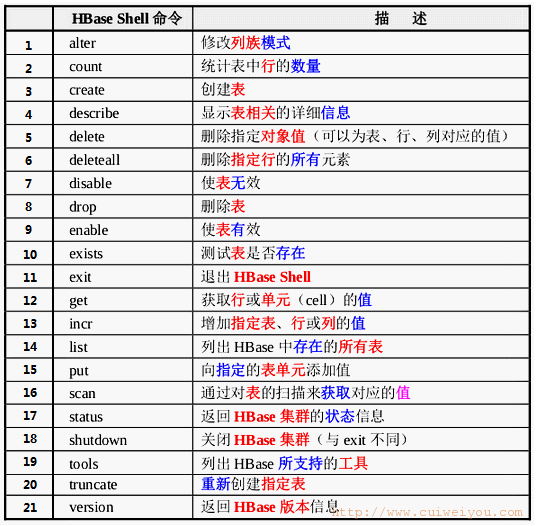
使用这些命令时,注意逗号、分号。
1.查看hbase状态-status
|
1 2 3 4 5 |
hbase(main):214:0> status 1 servers, 0 dead, 4.0000 average load #一个节点 hbase(main):215:0> |
2.创建表-create
|
1 2 3 4 5 6 |
hbase(main):006:0> create 'mytable1', 'family1','family2','family3' #create,表,列族,列族,列族... 0 row(s) in 0.6510 seconds => Hbase::Table - mytable1 #列族只能在创建表时同步创建 hbase(main):007:0> |
3.修改表-alter
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
hbase(main):212:0> alter #查看关于alter命令的信息 ERROR: wrong number of arguments (0 for 1) Here is some help for this command: 要修改表,如果"hbase.online.schema.update.enable"属性必须设为false, 那么同时表必须disabled; 如果"hbase.online.schema.update.enable"属性为true, 可不必设置表disable。 修改操作可能导致已创建的表出现问题,所以用于生产环境之前请谨慎操作并测试。 使用alter命令可以添加、修改、删除列族(column families)或改变表的配置选项。 列族(Column families)一般在使用create命令时同步创建。列族名称(column family specification)可以是字符串、存储一个字典的NAME属性。 Dictionaries are described in the output of the 'help' command, with no arguments. 举例,改变表't1'中已有的'f1'列族的单元格VERSIONS最小数量为5,这样: hbase> alter 't1', NAME => 'f1', VERSIONS => 5 你可以同时操作多个列族: hbase> alter 't1', 'f1', {NAME => 'f2', IN_MEMORY => true}, {NAME => 'f3', VERSIONS => 5} 从表'ns1:t1'中删除列族'f1',使用其中一种方式: hbase> alter 'ns1:t1', NAME => 'f1', METHOD => 'delete' #这个可用。ns1:t1即表名称,如mytable1 hbase> alter 'ns1:t1', 'delete' => 'f1' #测试没成 你还可以改变表的一些作用域属性,如:表region文件最大尺寸MAX_FILESIZE、READONLY、MEMSTORE_FLUSHSIZE、DURABILITY,等等。These can be put at the end; 举例,改变region文件的最大尺寸为128MB,这样: hbase> alter 't1', MAX_FILESIZE => '134217728' 你可以通过设置表的协处理器属性来添加一个表协处理器(table coprocessor): hbase> alter 't1', 'coprocessor'=>'hdfs:///foo.jar|com.foo.FooRegionObserver|1001|arg1=1,arg2=2' 实际上你能为表配置多个协处理器,一段连续数字将自动作为唯一属性名对它们标识。 协处理器coprocessor属性必须匹配以下模式,以使框架可以明确如何加载coprocessor类: [coprocessor jar file location] | class name | [priority] | [arguments] 你还可以为表或者列族设置特定的配置: hbase> alter 't1', CONFIGURATION => {'hbase.hregion.scan.loadColumnFamiliesOnDemand' => 'true'} hbase> alter 't1', {NAME => 'f2', CONFIGURATION => {'hbase.hstore.blockingStoreFiles' => '10'}} 你还可以移除一个表的作用域属性: hbase> alter 't1', METHOD => 'table_att_unset', NAME => 'MAX_FILESIZE' hbase> alter 't1', METHOD => 'table_att_unset', NAME => 'coprocessor$1' 你还可以设置region的备份数(REGION_REPLICATION): hbase> alter 't1', {REGION_REPLICATION => 2} 当然可以在一行命令中修改多项: hbase> alter 't1', { NAME => 'f1', VERSIONS => 3 }, { MAX_FILESIZE => '134217728' }, { METHOD => 'delete', NAME => 'f2' }, OWNER => 'johndoe', METADATA => { 'mykey' => 'myvalue' } hbase(main):213:0> hbase(main):205:0> alter 'mytable1', {NAME=>'family1', VERSIONS=>'3'} #改变指定列族的历史版本保存数量 Updating all regions with the new schema... #估计是当前版本的问题, 不执行此设置不保存历史版本 0/1 regions updated. 1/1 regions updated. Done. 0 row(s) in 2.5770 seconds hbase(main):206:0> |
4.打印全部表-list
|
1 2 3 4 5 6 7 8 |
hbase(main):007:0> list TABLE mytable1 1 row(s) in 0.0120 seconds => ["mytable1"] hbase(main):008:0> |
5.查看表描述-describe
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
hbase(main):010:0> describe 'mytable1' Table mytable1 is ENABLED #表的可用状态 mytable1 #表的名称 COLUMN FAMILIES DESCRIPTION #每一对大括号,对应一个列族 {NAME => 'family1', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VE RSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'F ALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'} {NAME => 'family2', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VE RSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'F ALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'} { NAME => 'family3', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true' } 3 row(s) in 0.0240 seconds hbase(main):011:0> root@debian:~# |
6.向表插入条目-put
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
hbase(main):002:0> put 'mytable1', 'row01', 'family1:column02', 'BigPig' #put,表,新行,已知列族:列,值 0 row(s) in 0.0060 seconds #这里说的列,即单元格 hbase(main):003:0> put 'mytable1', 'row01', 'family1:column03', 'Wooooo' #在同一行同一列族插入新列 0 row(s) in 0.0060 seconds hbase(main):004:0> put 'mytable1', 'row02', 'family2:column01', 'No Love ...' #在新行已知列族内插入新列 0 row(s) in 0.0100 seconds hbase(main):005:0> put 'mytable1', 'row02', 'family3:column01', 'No Love 222' 0 row(s) in 0.0090 seconds hbase(main):006:0> put 'mytable1', 'row02', 'family3:column02', 'Spring is comeing' 0 row(s) in 0.0050 seconds hbase(main):007:0> |
7.更新条目-put
|
1 2 3 4 5 6 7 |
hbase(main):012:0> put 'mytable1', 'row01', 'family1:column01', 'OldValue' #原值 0 row(s) in 0.0060 seconds hbase(main):013:0> put 'mytable1', 'row01', 'family1:column01', 'NewValue' #相同的位置,覆盖 0 row(s) in 0.0060 seconds hbase(main):014:0> |
8.查询条目-get
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
hbase(main):012:0> get 'mytable1', 'row02' #get,表,行 COLUMN CELL family2:column01 timestamp=1431416028195, value=No Love ... family3:column01 timestamp=1431416042541, value=No Love 222 family3:column02 timestamp=1431416071332, value=Spring is comeing 3 row(s) in 0.0120 seconds hbase(main):013:0> get 'mytable1', 'row02', 'family3' #get,表,行,列族 COLUMN CELL family3:column01 timestamp=1431416042541, value=No Love 222 family3:column02 timestamp=1431416071332, value=Spring is comeing 2 row(s) in 0.0390 seconds hbase(main):014:0> get 'mytable1', 'row02', 'family3:column02' #get,表,行,列族:列 COLUMN CELL family3:column02 timestamp=1431416071332, value=Spring is comeing 1 row(s) in 0.0230 seconds hbase(main):211:0> get 'mytable1', 'row01', {COLUMN=>'family1:column01', VERSIONS=>10} #查询单元格的历史版本 get 表, 行, {关键字COLUMN=>列族:列, 关键字VERSIONS=>历史版本数量} COLUMN CELL family1:column01 timestamp=1431420393165, value=9876 family1:column01 timestamp=1431420387772, value=xxxxBBB family1:column01 timestamp=1431420378258, value=BBBBB 3 row(s) in 0.0180 seconds hbase(main):212:0> |
9.打印表的全部条目-scan
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
hbase(main):007:0> scan 'mytable1' #打印整张表 ROW COLUMN+CELL row01 column=family1:column01, timestamp=1431415966581, value=BigData row01 column=family1:column02, timestamp=1431415988195, value=BigPig row01 column=family1:column03, timestamp=1431416001773, value=Wooooo row02 column=family2:column01, timestamp=1431416028195, value=No Love ... row02 column=family3:column01, timestamp=1431416042541, value=No Love 222 row02 column=family3:column02, timestamp=1431416071332, value=Spring is comeing 2 row(s) in 0.0870 seconds hbase(main):213:0> scan 'mytable1', {COLUMN=>'family1:column01',VERSIONS=>10} #扫描单元格历史版本 ROW COLUMN+CELL row01 column=family1:column01, timestamp=1431420393165, value=9876 row01 column=family1:column01, timestamp=1431420387772, value=xxxxBBB row01 column=family1:column01, timestamp=1431420378258, value=BBBBB 1 row(s) in 0.0230 seconds hbase(main):214:0> |
10.删除条目-delete
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
hbase(main):299:0> scan 'mytable1' ROW COLUMN+CELL row01 column=family1:column01, timestamp=1431420393165, value=9876 row01 column=family1:column02, timestamp=1431415988195, value=BigPig row01 column=family1:column03, timestamp=1431416001773, value=Wooooo row02 column=family3:column01, timestamp=1431416042541, value=No Love 222 row02 column=family3:column02, timestamp=1431417679202, value=45678909876543 2 row(s) in 0.0420 seconds hbase(main):300:0> delete 'mytable1', 'row02', 'family3:column02' #delete,表,行,列族:列 0 row(s) in 0.0110 seconds hbase(main):301:0> scan 'mytable1' ROW COLUMN+CELL row01 column=family1:column01, timestamp=1431420393165, value=9876 row01 column=family1:column02, timestamp=1431415988195, value=BigPig row01 column=family1:column03, timestamp=1431416001773, value=Wooooo row02 column=family3:column01, timestamp=1431416042541, value=No Love 222 2 row(s) in 0.0910 seconds hbase(main):302:0> |
11.删除行-deleteall
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
hbase(main):303:0> scan 'mytable1' ROW COLUMN+CELL row01 column=family1:column01, timestamp=1431420393165, value=9876 row01 column=family1:column02, timestamp=1431415988195, value=BigPig row01 column=family1:column03, timestamp=1431416001773, value=Wooooo row02 column=family3:column01, timestamp=1431416042541, value=No Love 222 2 row(s) in 0.0200 seconds hbase(main):304:0> deleteall 'mytable1', 'row02' #deleteall 表,行 0 row(s) in 0.0190 seconds hbase(main):305:0> scan 'mytable1' ROW COLUMN+CELL row01 column=family1:column01, timestamp=1431420393165, value=9876 row01 column=family1:column02, timestamp=1431415988195, value=BigPig row01 column=family1:column03, timestamp=1431416001773, value=Wooooo 1 row(s) in 0.0560 seconds hbase(main):306:0> |
12.清空表/重新建表-truncate
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
hbase(main):307:0> scan 'mytable1' ROW COLUMN+CELL row01 column=family1:column01, timestamp=1431420393165, value=9876 row01 column=family1:column02, timestamp=1431415988195, value=BigPig row01 column=family1:column03, timestamp=1431416001773, value=Wooooo 1 row(s) in 0.0140 seconds hbase(main):309:0> truncate 'mytable1' #现有的列族不发生变化,仅清除全部单元格 Truncating 'mytable1' table (it may take a while): - Disabling table... - Truncating table... 0 row(s) in 3.2680 seconds hbase(main):310:0> scan 'mytable1' ROW COLUMN+CELL 0 row(s) in 0.3580 seconds hbase(main):311:0> |
13.统计表的条目总量-count
|
1 2 3 4 5 6 7 8 9 10 11 12 |
hbase(main):307:0> scan 'mytable1' ROW COLUMN+CELL row01 column=family1:column01, timestamp=1431420393165, value=9876 row01 column=family1:column02, timestamp=1431415988195, value=BigPig row01 column=family1:column03, timestamp=1431416001773, value=Wooooo 1 row(s) in 0.0140 seconds hbase(main):308:0> count 'mytable1' #统计 1 row(s) in 0.0610 seconds #只有一行 => 1 hbase(main):309:0> |
14.关闭并删除表-disable、drop
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
hbase(main):002:0> list TABLE mytable mytable1 t1 3 row(s) in 0.3570 seconds => ["mytable", "mytable1", "t1"] hbase(main):003:0> scan 'mytable1' ROW COLUMN+CELL 0 row(s) in 0.9310 seconds hbase(main):004:0> drop 'mytable' ERROR: Table mytable is enabled. Disable it first. Here is some help for this command: Drop the named table. Table must first be disabled: hbase> drop 't1' hbase> drop 'ns1:t1' hbase(main):005:0> disable 'mytable' #首先关闭表 0 row(s) in 1.2520 seconds hbase(main):006:0> drop 'mytable' #然后删除表 0 row(s) in 0.2620 seconds hbase(main):007:0> list TABLE mytable1 t1 2 row(s) in 0.0400 seconds => ["mytable1", "t1"] hbase(main):008:0> |
三。常用的HBase JavaAPI

1.建表
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
package com.cuiweiyou.test; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.util.Bytes; import org.junit.Test; public class HBaseTest { // 1.创建表 @Test public void testCreatTable() throws Exception { String strTBName = "tb1"; // 表 String strColFamily1 = "cf1"; // 列族 String strColFamily2 = "cf2"; // 列族 // 1)表名称 TableName tableName = TableName.valueOf(strTBName); // 2)表描述器 HTableDescriptor tableDesc = new HTableDescriptor(tableName); tableDesc.addFamily(new HColumnDescriptor(strColFamily1));// 添加列族 tableDesc.addFamily(new HColumnDescriptor(strColFamily2));// 添加列族 // 3)配置 Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "localhost"); // 4)管理员 // HBaseAdmin hbaseAdmin = new HBaseAdmin(conf); //过时的方法 Connection connection = ConnectionFactory.createConnection(conf); Admin admin = connection.getAdmin(); // 0.99.0版本出现 // 创建一个表 admin.createTable(tableDesc); /* * 以下3种建表方法:提前分配region可减少Split节省时间 * 但如果region数过多,会报这个SocketTimeoutException异常-建表超时 */ // 1. // 指定表的“起始行键”、“末尾行键”和region的数量 // 这样系统自动给你划分region。根据的region数,来均分所有的行键。 // 问题是如果你的表的行键不是连续的,那样的话就导致有些region的行键不会用到,有些region是全满的 // createTable(HTableDescriptor desc, byte[] startKey, byte[] endKey, // int numRegions) // 2.splitKeys是一个二维字节数组,数组中行数量+1即region的数量,数组的列就是region中的行键 // createTable(HTableDescriptor desc, byte[][] splitKeys) // 3.同方法2,但这个是异步的。 // createTableAsync(HTableDescriptor desc, byte[][] splitKeys) System.out.println("建表操作完成"); } } |
org.apache.hadoop.hbase.client.Admin
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 |
void abort(String why, Throwable e) 中断服务器或客户端 void addColumn(TableName tableName, HColumnDescriptor column) 向已存在的表中插入列 void assign(byte[] regionName) 分配? boolean balancer() 调用平衡器 void cloneSnapshot(byte[] snapshotName, TableName tableName) 通过克隆快照内容创建多个新表。 void cloneSnapshot(String snapshotName, TableName tableName) 通过克隆快照内容创建新表。 void close() 关闭? void closeRegion(byte[] regionname, String serverName) 关闭多个region. void closeRegion(ServerName sn, HRegionInfo hri) 关闭一个region void closeRegion(String regionname, String serverName) 关闭一个region boolean closeRegionWithEncodedRegionName(String encodedRegionName, String serverName) For expert-admins. void compact(TableName tableName) 压缩表? void compact(TableName tableName, byte[] columnFamily) 压缩表中的指定列族 void compactRegion(byte[] regionName) 压缩多个指定region(individual region) void compactRegion(byte[] regionName, byte[] columnFamily) Compact a column family within a region. void compactRegionServer(ServerName sn, boolean major) Compact all regions on the region server CoprocessorRpcChannel coprocessorService() Creates and returns a RpcChannel instance connected to the active master. CoprocessorRpcChannel coprocessorService(ServerName sn) Creates and returns a RpcChannel instance connected to the passed region server. void createNamespace(NamespaceDescriptor descriptor) Create a new namespace void createTable(HTableDescriptor desc) Creates a new table. void createTable(HTableDescriptor desc, byte[][] splitKeys) Creates a new table with an initial set of empty regions defined by the specified split keys. void createTable(HTableDescriptor desc, byte[] startKey, byte[] endKey, int numRegions) Creates a new table with the specified number of regions. void createTableAsync(HTableDescriptor desc, byte[][] splitKeys) Creates a new table but does not block and wait for it to come online. void deleteColumn(TableName tableName, byte[] columnName) Delete a column from a table. void deleteNamespace(String name) Delete an existing namespace. void deleteSnapshot(byte[] snapshotName) Delete an existing snapshot. void deleteSnapshot(String snapshotName) Delete an existing snapshot. void deleteSnapshots(Pattern pattern) Delete existing snapshots whose names match the pattern passed. void deleteSnapshots(String regex) Delete existing snapshots whose names match the pattern passed. void deleteTable(TableName tableName) Deletes a table. HTableDescriptor[] deleteTables(Pattern pattern) Delete tables matching the passed in pattern and wait on completion. HTableDescriptor[] deleteTables(String regex) Deletes tables matching the passed in pattern and wait on completion. void disableTable(TableName tableName) Disable table and wait on completion. void disableTableAsync(TableName tableName) Starts the disable of a table. HTableDescriptor[] disableTables(Pattern pattern) Disable tables matching the passed in pattern and wait on completion. HTableDescriptor[] disableTables(String regex) Disable tables matching the passed in pattern and wait on completion. boolean enableCatalogJanitor(boolean enable) Enable/Disable the catalog janitor void enableTable(TableName tableName) Enable a table. void enableTableAsync(TableName tableName) Brings a table on-line (enables it). HTableDescriptor[] enableTables(Pattern pattern) Enable tables matching the passed in pattern and wait on completion. HTableDescriptor[] enableTables(String regex) Enable tables matching the passed in pattern and wait on completion. void execProcedure(String signature, String instance, Map<String,String> props) Execute a distributed procedure on a cluster. byte[] execProcedureWithRet(String signature, String instance, Map<String,String> props) Execute a distributed procedure on a cluster. void flush(TableName tableName) Flush a table. void flushRegion(byte[] regionName) Flush an individual region. Pair<Integer,Integer> getAlterStatus(byte[] tableName) Get the status of alter command - indicates how many regions have received the updated schema Asynchronous operation. Pair<Integer,Integer> getAlterStatus(TableName tableName) Get the status of alter command - indicates how many regions have received the updated schema Asynchronous operation. ClusterStatus getClusterStatus() xxx org.apache.hadoop.hbase.protobuf.generated.AdminProtos.GetRegionInfoResponse.CompactionState getCompactionState(TableName tableName) Get the current compaction state of a table. org.apache.hadoop.hbase.protobuf.generated.AdminProtos.GetRegionInfoResponse.CompactionState getCompactionStateForRegion(byte[] regionName) Get the current compaction state of region. org.apache.hadoop.conf.Configuration getConfiguration() xxx Connection getConnection() xxx String[] getMasterCoprocessors() xxx Helper delegage to getClusterStatus().getMasterCoprocessors(). xxx int getMasterInfoPort() Get the info port of the current master if one is available. NamespaceDescriptor getNamespaceDescriptor(String name) Get a namespace descriptor by name List<HRegionInfo> getOnlineRegions(ServerName sn) Get all the online regions on a region server. int getOperationTimeout() xxx HTableDescriptor getTableDescriptor(TableName tableName) Method for getting the tableDescriptor HTableDescriptor[] getTableDescriptors(List<String> names) Get tableDescriptors HTableDescriptor[] getTableDescriptorsByTableName(List<TableName> tableNames) Get tableDescriptors List<HRegionInfo> getTableRegions(TableName tableName) Get the regions of a given table. boolean isAborted() Check if the server or client was aborted. boolean isCatalogJanitorEnabled() Query on the catalog janitor state (Enabled/Disabled?) boolean isProcedureFinished(String signature, String instance, Map<String,String> props) Check the current state of the specified procedure. boolean isSnapshotFinished(org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.SnapshotDescription snapshot) Check the current state of the passed snapshot. boolean isTableAvailable(TableName tableName) xxx boolean isTableAvailable(TableName tableName, byte[][] splitKeys) Use this api to check if the table has been created with the specified number of splitkeys which was used while creating the given table. boolean isTableDisabled(TableName tableName) xxx boolean isTableEnabled(TableName tableName) xxx NamespaceDescriptor[] listNamespaceDescriptors() List available namespace descriptors List<org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.SnapshotDescription> listSnapshots() List completed snapshots. List<org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.SnapshotDescription> xxx listSnapshots(Pattern pattern) List all the completed snapshots matching the given pattern. List<org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.SnapshotDescription> listSnapshots(String regex) List all the completed snapshots matching the given regular expression. HTableDescriptor[] listTableDescriptorsByNamespace(String name) Get list of table descriptors by namespace TableName[] listTableNames() List all of the names of userspace tables. TableName[] listTableNames(Pattern pattern) List all of the names of userspace tables. TableName[] listTableNames(Pattern pattern, boolean includeSysTables) List all of the names of userspace tables. TableName[] listTableNames(String regex) List all of the names of userspace tables. TableName[] listTableNames(String regex, boolean includeSysTables) List all of the names of userspace tables. TableName[] listTableNamesByNamespace(String name) Get list of table names by namespace HTableDescriptor[] listTables() List all the userspace tables. HTableDescriptor[] listTables(Pattern pattern) List all the userspace tables matching the given pattern. HTableDescriptor[] listTables(Pattern pattern, boolean includeSysTables) List all the tables matching the given pattern. HTableDescriptor[] listTables(String regex) List all the userspace tables matching the given regular expression. HTableDescriptor[] listTables(String regex, boolean includeSysTables) List all the tables matching the given pattern. void majorCompact(TableName tableName) Major compact a table. void majorCompact(TableName tableName, byte[] columnFamily) Major compact a column family within a table. void majorCompactRegion(byte[] regionName) Major compact a table or an individual region. void majorCompactRegion(byte[] regionName, byte[] columnFamily) Major compact a column family within region. void mergeRegions(byte[] encodedNameOfRegionA, byte[] encodedNameOfRegionB, boolean forcible) Merge two regions. void modifyColumn(TableName tableName, HColumnDescriptor descriptor) Modify an existing column family on a table. void modifyNamespace(NamespaceDescriptor descriptor) Modify an existing namespace void modifyTable(TableName tableName, HTableDescriptor htd) 修改表的模式。Modify an existing table, more IRB friendly version. void move(byte[] encodedRegionName, byte[] destServerName) Move the region r to dest. void offline(byte[] regionName) Offline specified region from master's in-memory state. void restoreSnapshot(byte[] snapshotName) Restore the specified snapshot on the original table. void restoreSnapshot(byte[] snapshotName, boolean takeFailSafeSnapshot) Restore the specified snapshot on the original table. void restoreSnapshot(String snapshotName) Restore the specified snapshot on the original table. void restoreSnapshot(String snapshotName, boolean takeFailSafeSnapshot) Restore the specified snapshot on the original table. void rollWALWriter(ServerName serverName) Roll the log writer. int runCatalogScan() Ask for a scan of the catalog table boolean setBalancerRunning(boolean on, boolean synchronous) Turn the load balancer on or off. void shutdown() Shuts down the HBase cluster void snapshot(byte[] snapshotName, TableName tableName) Create a timestamp consistent snapshot for the given table. void snapshot(org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.SnapshotDescription snapshot) Take a snapshot and wait for the server to complete that snapshot (blocking). void snapshot(String snapshotName, TableName tableName) Take a snapshot for the given table. void snapshot(String snapshotName, TableName tableName, org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.SnapshotDescription.Type type) Create typed snapshot of the table. void split(TableName tableName) Split a table. void split(TableName tableName, byte[] splitPoint) Split a table. void splitRegion(byte[] regionName) Split an individual region. void splitRegion(byte[] regionName, byte[] splitPoint) Split an individual region. void stopMaster() Shuts down the current HBase master only. void stopRegionServer(String hostnamePort) Stop the designated regionserver boolean tableExists(TableName tableName) 检查表是否存在 org.apache.hadoop.hbase.protobuf.generated.MasterProtos.SnapshotResponse takeSnapshotAsync(org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.SnapshotDescription snapshot) Take a snapshot without waiting for the server to complete that snapshot (asynchronous) Only a single snapshot should be taken at a time, or results may be undefined. void truncateTable(TableName tableName, boolean preserveSplits) Truncate a table. void unassign(byte[] regionName, boolean force) Unassign a region from current hosting regionserver. void updateConfiguration() Update the configuration and trigger an online config change on all the regionservers void updateConfiguration(ServerName server) Update the configuration and trigger an online config change on the regionserver |
org.apache.hadoop.hbase.HTableDescriptor
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
static String COMPACTION_ENABLED INTERNAL Used by HBase Shell interface to access this metadata attribute which denotes if the table is compaction enabled static boolean DEFAULT_COMPACTION_ENABLED Constant that denotes whether the table is compaction enabled by default static long DEFAULT_MEMSTORE_FLUSH_SIZE Constant that denotes the maximum default size of the memstore after which the contents are flushed to the store files static boolean DEFAULT_READONLY Constant that denotes whether the table is READONLY by default and is false static int DEFAULT_REGION_REPLICATION xxx static String DEFERRED_LOG_FLUSH Deprecated. Use DURABILITY instead. static String DURABILITY INTERNAL Durability setting for the table. static String IS_META INTERNAL Used by rest interface to access this metadata attribute which denotes if it is a catalog table, either hbase:meta or -ROOT- static String IS_ROOT INTERNAL Used by rest interface to access this metadata attribute which denotes if the table is a -ROOT- region or not static String MAX_FILESIZE INTERNAL Used by HBase Shell interface to access this metadata attribute which denotes the maximum size of the store file after which a region split occurs static String MEMSTORE_FLUSHSIZE INTERNAL Used by HBase Shell interface to access this metadata attribute which represents the maximum size of the memstore after which its contents are flushed onto the disk static HTableDescriptor META_TABLEDESC Deprecated.Use TableDescriptors#get(TableName.META_TABLE_NAME) or HBaseAdmin#getTableDescriptor(TableName.META_TABLE_NAME) instead. static byte[] NAMESPACE_COL_DESC_BYTES xxx static String NAMESPACE_FAMILY_INFO xxx static byte[] NAMESPACE_FAMILY_INFO_BYTES xxx static HTableDescriptor NAMESPACE_TABLEDESC Table descriptor for namespace table static String OWNER xxx static ImmutableBytesWrita xxxble OWNER_KEY static String READONLY INTERNAL Used by rest interface to access this metadata attribute which denotes if the table is Read Only static String REGION_REPLICATION INTERNAL number of region replicas for the table. static String SPLIT_POLICY xxx |
2.插入/更新单元格
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
@Test public void testCreateCell() throws IOException { String tableName = "tb1"; String colFamily = "cf1"; String rowKey = "row1"; // 行号 String column = "col1"; // 列名 String value = "value1"; // 值 // 配置器 Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "localhost"); // 表实例 // HTable table = new HTable(conf, tableName); //@Deprecated过时 Connection connection = ConnectionFactory.createConnection(conf); Table table = connection.getTable(TableName.valueOf(tableName)); // 获取表中全部的列族 HColumnDescriptor[] columnFamilies = table.getTableDescriptor().getColumnFamilies(); // 插入器 Put put = new Put(Bytes.toBytes(rowKey));// 设置行号,RowKey // 遍历列族,找到匹配的列族 for (int i = 0; i < columnFamilies.length; i++) { String familyName = columnFamilies[i].getNameAsString(); // 获取列族名 // 如果是指定列族 if (familyName.equals(colFamily)) { // 插入 //put.add(Bytes.toBytes(familyName), Bytes.toBytes(strColumn), Bytes.toBytes(strValue)); // 过时 put.addColumn(Bytes.toBytes(familyName), Bytes.toBytes(column), Bytes.toBytes(value)); } } table.put(put); // 运行插入器 System.out.println("插入操作执行完毕"); } |
org.apache.hadoop.hbase.client.Table
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
Result append(Append append) Appends values to one or more columns within a single row. Object[] batch(List<? extends Row> actions) Deprecated.If any exception is thrown by one of the actions, there is no way to retrieve the partially executed results. Use batch(List, Object[]) instead. void batch(List<? extends Row> actions, Object[] results) Method that does a batch call on Deletes, Gets, Puts, Increments and Appends. <R> Object[] batchCallback(List<? extends Row> actions, org.apache.hadoop.hbase.client.coprocessor.Batch.Callback<R> callback) Deprecated.If any exception is thrown by one of the actions, there is no way to retrieve the partially executed results. Use batchCallback(List, Object[], org.apache.hadoop.hbase.client.coprocessor.Batch.Callback) instead. <R> void batchCallback(List<? extends Row> actions, Object[] results, org.apache.hadoop.hbase.client.coprocessor.Batch.Callback<R> callback) Same as batch(List, Object[]), but with a callback. <R extends com.google.protobuf.Message> Map<byte[],R> batchCoprocessorService(com.google.protobuf.Descriptors.MethodDescriptor methodDescriptor, com.google.protobuf.Message request, byte[] startKey, byte[] endKey, R responsePrototype) Creates an instance of the given Service subclass for each table region spanning the range from the startKey row to endKey row (inclusive), all the invocations to the same region server will be batched into one call. <R extends com.google.protobuf.Message> void batchCoprocessorService(com.google.protobuf.Descriptors.MethodDescriptor methodDescriptor, com.google.protobuf.Message request, byte[] startKey, byte[] endKey, R responsePrototype, org.apache.hadoop.hbase.client.coprocessor.Batch.Callback<R> callback) Creates an instance of the given Service subclass for each table region spanning the range from the startKey row to endKey row (inclusive), all the invocations to the same region server will be batched into one call. boolean checkAndDelete(byte[] row, byte[] family, byte[] qualifier, byte[] value, Delete delete) Atomically checks if a row/family/qualifier value matches the expected value. boolean checkAndDelete(byte[] row, byte[] family, byte[] qualifier, CompareFilter.CompareOp compareOp, byte[] value, Delete delete) Atomically checks if a row/family/qualifier value matches the expected value. boolean checkAndMutate(byte[] row, byte[] family, byte[] qualifier, CompareFilter.CompareOp compareOp, byte[] value, RowMutations mutation) Atomically checks if a row/family/qualifier value matches the expected value. boolean checkAndPut(byte[] row, byte[] family, byte[] qualifier, byte[] value, Put put) Atomically checks if a row/family/qualifier value matches the expected value. boolean checkAndPut(byte[] row, byte[] family, byte[] qualifier, CompareFilter.CompareOp compareOp, byte[] value, Put put) Atomically checks if a row/family/qualifier value matches the expected value. void close() 释放所有的资源或挂起内部缓冲区中的更新。Releases any resources held or pending changes in internal buffers. CoprocessorRpcChannel coprocessorService(byte[] row) Creates and returns a RpcChannel instance connected to the table region containing the specified row. <T extends com.google.protobuf.Service,R> Map<byte[],R> coprocessorService(Class<T> service, byte[] startKey, byte[] endKey, org.apache.hadoop.hbase.client.coprocessor.Batch.Call<T,R> callable) Creates an instance of the given Service subclass for each table region spanning the range from the startKey row to endKey row (inclusive), and invokes the passed Batch.Call.call(T) method with each Service instance. <T extends com.google.protobuf.Service,R> void coprocessorService(Class<T> service, byte[] startKey, byte[] endKey, org.apache.hadoop.hbase.client.coprocessor.Batch.Call<T,R> callable, org.apache.hadoop.hbase.client.coprocessor.Batch.Callback<R> callback) Creates an instance of the given Service subclass for each table region spanning the range from the startKey row to endKey row (inclusive), and invokes the passed Batch.Call.call(T) method with each Service instance. void delete(Delete delete) Deletes the specified cells/row. void delete(List<Delete> deletes) Deletes the specified cells/rows in bulk. boolean exists(Get get) 检查Get实例所指定的值是否存在于HTable的列中。Test for the existence of columns in the table, as specified by the Get. boolean[] existsAll(List<Get> gets) Test for the existence of columns in the table, as specified by the Gets. Result get(Get get) 获取指定行的某些单元格所对应的值。Extracts certain cells from a given row. Result[] get(List<Get> gets) Extracts certain cells from the given rows, in batch. org.apache.hadoop.conf.Configuration getConfiguration() Returns the Configuration object used by this instance. TableName getName() 获取表名。Gets the fully qualified table name instance of this table. ResultScanner getScanner(byte[] family) 获取当前给定列族的scanner实例。Gets a scanner on the current table for the given family. ResultScanner getScanner(byte[] family, byte[] qualifier) Gets a scanner on the current table for the given family and qualifier. ResultScanner getScanner(Scan scan) Returns a scanner on the current table as specified by the Scan object. HTableDescriptor getTableDescriptor() 获取当前表的HTableDescriptor实例。Gets the table descriptor for this table. long getWriteBufferSize() Deprecated. as of 1.0.1 (should not have been in 1.0.0). Replaced by BufferedMutator.getWriteBufferSize() Result increment(Increment increment) Increments one or more columns within a single row. long incrementColumnValue(byte[] row, byte[] family, byte[] qualifier, long amount) 查看方法 incrementColumnValue(byte[], byte[], byte[], long, Durability) (链接失效) long incrementColumnValue(byte[] row, byte[] family, byte[] qualifier, long amount, Durability durability) Atomically increments a column value. void mutateRow(RowMutations rm) Performs multiple mutations atomically on a single row. void put(List<Put> puts) Puts some data in the table, in batch. void put(Put put) Puts some data in the table. void setWriteBufferSize(long writeBufferSize) Deprecated.as of 1.0.1 (should not have been in 1.0.0). Replaced by BufferedMutator and BufferedMutatorParams.writeBufferSize(long) |
org.apache.hadoop.hbase.HColumnDescriptor
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 |
int compareTo(HColumnDescriptor o) xxx org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.ColumnFamilySchema convert() xxx static HColumnDescriptor convert(org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.ColumnFamilySchema cfs) xxx boolean equals(Object obj) xxx int getBlocksize() xxx BloomType getBloomFilterType() xxx Compression.Algorithm getCompactionCompression() xxx Compression.Algorithm getCompactionCompressionType() xxx Compression.Algorithm getCompression() xxx Compression.Algorithm getCompressionType() xxx Map<String,String> getConfiguration() Getter for fetching an unmodifiable configuration map. String getConfigurationValue(String key) Getter for accessing the configuration value by key. DataBlockEncoding getDataBlockEncoding() xxx DataBlockEncoding getDataBlockEncodingOnDisk() Deprecated. static Map<String,String> getDefaultValues() xxx byte[] getEncryptionKey() Return the raw crypto key attribute for the family, or null if not set String getEncryptionType() Return the encryption algorithm in use by this family KeepDeletedCells getKeepDeletedCells() xxx int getMaxVersions() xxx int getMinVersions() xxx byte[] getName() 获取列族的名字 String getNameAsString() xxx int getScope() xxx int getTimeToLive() xxx static org.apache.hadoop.hbase.util.PrettyPrinter.Unit getUnit(String key) xxx byte[] getValue(byte[] key) 获取对应的属性的值。xxx String getValue(String key) xxx Map<ImmutableBytesWritable,ImmutableBytesWritable> getValues() xxx int hashCode() xxx boolean isBlockCacheEnabled() xxx boolean isCacheBloomsOnWrite() xxx boolean isCacheDataInL1() xxx boolean isCacheDataOnWrite() xxx boolean isCacheIndexesOnWrite() xxx boolean isCompressTags() xxx boolean isEvictBlocksOnClose() xxx boolean isInMemory() xxx static byte[] isLegalFamilyName(byte[] b) xxx boolean isPrefetchBlocksOnOpen() xxx static HColumnDescriptor parseFrom(byte[] bytes) xxx void readFields(DataInput in) Deprecated.Writables are going away. Use pb parseFrom(byte[]) instead. void remove(byte[] key) xxx void removeConfiguration(String key) Remove a configuration setting represented by the key from the configuration map. HColumnDescriptor setBlockCacheEnabled(boolean blockCacheEnabled) xxx HColumnDescriptor setBlocksize(int s) xxx HColumnDescriptor setBloomFilterType(BloomType bt) xxx HColumnDescriptor setCacheBloomsOnWrite(boolean value) xxx HColumnDescriptor setCacheDataInL1(boolean value) xxx HColumnDescriptor setCacheDataOnWrite(boolean value) xxx HColumnDescriptor setCacheIndexesOnWrite(boolean value) xxx HColumnDescriptor setCompactionCompressionType(Compression.Algorithm type) Compression types supported in hbase. HColumnDescriptor setCompressionType(Compression.Algorithm type) Compression types supported in hbase. HColumnDescriptor setCompressTags(boolean compressTags) Set whether the tags should be compressed along with DataBlockEncoding. HColumnDescriptor setConfiguration(String key, String value) Setter for storing a configuration setting in configuration map. HColumnDescriptor setDataBlockEncoding(DataBlockEncoding type) Set data block encoding algorithm used in block cache. HColumnDescriptor setEncodeOnDisk(boolean encodeOnDisk) Deprecated. HColumnDescriptor setEncryptionKey(byte[] keyBytes) Set the raw crypto key attribute for the family HColumnDescriptor setEncryptionType(String algorithm) Set the encryption algorithm for use with this family HColumnDescriptor setEvictBlocksOnClose(boolean value) xxx HColumnDescriptor setInMemory(boolean inMemory) xxx HColumnDescriptor setKeepDeletedCells(boolean keepDeletedCells) Deprecated.使用这个方法 setKeepDeletedCells(KeepDeletedCells) HColumnDescriptor setKeepDeletedCells(KeepDeletedCells keepDeletedCells) xxx HColumnDescriptor setMaxVersions(int maxVersions) xxx HColumnDescriptor setMinVersions(int minVersions) xxx HColumnDescriptor setPrefetchBlocksOnOpen(boolean value) xxx HColumnDescriptor setScope(int scope) xxx HColumnDescriptor setTimeToLive(int timeToLive) xxx HColumnDescriptor setValue(byte[] key, byte[] value) 设置对应属性的值。xxx HColumnDescriptor setValue(String key, String value) xxx boolean shouldCacheBloomsOnWrite() Deprecated。使用isCacheBloomsOnWrite() 替代 boolean shouldCacheDataInL1() Deprecated. 使用Use isCacheDataInL1() 替代 boolean shouldCacheDataOnWrite() Deprecated. 使用Use isCacheDataOnWrite() 替代 boolean shouldCacheIndexesOnWrite() Deprecated.使用Use isCacheIndexesOnWrite() 替代 boolean shouldCompressTags() Deprecated。使用Use isCompressTags() 替代 boolean shouldEvictBlocksOnClose() Deprecated. 由isEvictBlocksOnClose()替代 boolean shouldPrefetchBlocksOnOpen() Deprecated. 使用isPrefetchBlocksOnOpen() 替代 byte[] toByteArray() xxx String toString() xxx String toStringCustomizedValues() xxx void write(DataOutput out) Deprecated.使用Writables are going away. Use toByteArray() 替代. |
org.apache.hadoop.hbase.client.Put
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |
Put add(byte[] family, byte[] qualifier, byte[] value) Deprecated过时,从1.0.0开始使用 addColumn(byte[], byte[], byte[])替换,将指定的列和对应的值添加到Put实例中 Put add(byte[] family, byte[] qualifier, long ts, byte[] value) Deprecated过时,从1.0.0开始使用 addColumn(byte[], byte[], long, byte[]) 替换,将指定的列和对应的值及时间戳添加到Put实例中 Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) Deprecated过时,从1.0.0开始使用 addColumn(byte[], ByteBuffer, long, ByteBuffer) 替换 Put add(Cell kv) Add the specified KeyValue to this Put operation. Put addColumn(byte[] family, byte[] qualifier, byte[] value) Add the specified column and value to this Put operation. Put addColumn(byte[] family, byte[] qualifier, long ts, byte[] value) Add the specified column and value, with the specified timestamp as its version to this Put operation. Put addColumn(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) Add the specified column and value, with the specified timestamp as its version to this Put operation. Put addImmutable(byte[] family, byte[] qualifier, byte[] value) See add(byte[], byte[], byte[]). Put addImmutable(byte[] family, byte[] qualifier, byte[] value, org.apache.hadoop.hbase.Tag[] tag) This expects that the underlying arrays won't change. Put addImmutable(byte[] family, byte[] qualifier, long ts, byte[] value) See add(byte[], byte[], long, byte[]). Put addImmutable(byte[] family, byte[] qualifier, long ts, byte[] value, org.apache.hadoop.hbase.Tag[] tag) This expects that the underlying arrays won't change. Put addImmutable(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) See add(byte[], ByteBuffer, long, ByteBuffer). Put addImmutable(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value, org.apache.hadoop.hbase.Tag[] tag) This expects that the underlying arrays won't change. List<Cell> get(byte[] family, byte[] qualifier) Returns a list of all KeyValue objects with matching column family and qualifier. boolean has(byte[] family, byte[] qualifier) A convenience method to determine if this object's familyMap contains a value assigned to the given family & qualifier. boolean has(byte[] family, byte[] qualifier, byte[] value) A convenience method to determine if this object's familyMap contains a value assigned to the given family, qualifier and timestamp. boolean has(byte[] family, byte[] qualifier, long ts) A convenience method to determine if this object's familyMap contains a value assigned to the given family, qualifier and timestamp. boolean has(byte[] family, byte[] qualifier, long ts, byte[] value) A convenience method to determine if this object's familyMap contains the given value assigned to the given family, qualifier and timestamp. Put setACL(Map<String,org.apache.hadoop.hbase.security.access.Permission> perms) xxx Put setACL(String user, org.apache.hadoop.hbase.security.access.Permission perms) xxx Put setAttribute(String name, byte[] value) Sets an attribute. Put setCellVisibility(org.apache.hadoop.hbase.security.visibility.CellVisibility expression) Sets the visibility expression associated with cells in this Mutation. Put setClusterIds(List<UUID> clusterIds) Marks that the clusters with the given clusterIds have consumed the mutation Put setDurability(Durability d) Set the durability for this mutation Put setFamilyCellMap(NavigableMap<byte[],List<Cell>> map) Method for setting the put's familyMap Put setFamilyMap(NavigableMap<byte[],List<org.apache.hadoop.hbase.KeyValue>> map) Deprecated. Put setId(String id) This method allows you to set an identifier on an operation. Put setTTL(long ttl) Set the TTL desired for the result of the mutation, in milliseconds. Put setWriteToWAL(boolean write) Deprecated. -------------- 以下由父类org.apache.hadoop.hbase.client.Mutation 继承 ---------------- org.apache.hadoop.hbase.CellScanner cellScanner() xxx int compareTo(Row d) xxx protected long extraHeapSize() Subclasses should override this method to add the heap size of their own fields. byte[] getACL() xxx org.apache.hadoop.hbase.security.visibility.CellVisibility getCellVisibility() xxx List<UUID> getClusterIds() xxx Durability getDurability() Get the current durability NavigableMap<byte[],List<Cell>> getFamilyCellMap() Method for retrieving the put's familyMap NavigableMap<byte[],List<org.apache.hadoop.hbase.KeyValue>> getFamilyMap() Deprecated. use getFamilyCellMap() instead. Map<String,Object> getFingerprint() Compile the column family (i.e. byte[] getRow() 获取Put实例的行。Method for retrieving the delete's row long getTimeStamp() 获取Put实例的时间戳。Method for retrieving the timestamp long getTTL() Return the TTL requested for the result of the mutation, in milliseconds. boolean getWriteToWAL() Deprecated. Use getDurability() instead. long heapSize() xxx boolean isEmpty() 检查familyMap是否为空。Method to check if the familyMap is empty int numFamilies() xxx Mutation setACL(Map<String,org.apache.hadoop.hbase.security.access.Permission> perms) xxx Mutation setACL(String user, org.apache.hadoop.hbase.security.access.Permission perms) xxx Mutation setCellVisibility(org.apache.hadoop.hbase.security.visibility.CellVisibility expression) Sets the visibility expression associated with cells in this Mutation. Mutation setClusterIds(List<UUID> clusterIds) Marks that the clusters with the given clusterIds have consumed the mutation Mutation setDurability(Durability d) Set the durability for this mutation Mutation setFamilyCellMap(NavigableMap<byte[],List<Cell>> map) Method for setting the put's familyMap Mutation setFamilyMap(NavigableMap<byte[],List<org.apache.hadoop.hbase.KeyValue>> map) Deprecated. use setFamilyCellMap(NavigableMap) instead. Mutation setTTL(long ttl) Set the TTL desired for the result of the mutation, in milliseconds. Mutation setWriteToWAL(boolean write) Deprecated. Use setDurability(Durability) instead. int size() Number of KeyValues carried by this Mutation. Map<String,Object> toMap(int maxCols) Compile the details beyond the scope of getFingerprint (row, columns, timestamps, etc.) into a Map along with the fingerprinted information. |
3.读取单元格
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
@Test public void testGetRow() throws IOException { String tableName = "tb1"; String rowKey = "row1"; // 配置器 Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "localhost"); // 表实例 Connection connection = ConnectionFactory.createConnection(conf); Table table = connection.getTable(TableName.valueOf(tableName)); // 查询器 Get get = new Get(Bytes.toBytes(rowKey)); //查询指定行 // 结果实例 Result result = table.get(get); //执行查询 // 单元格集合 List<Cell> listCells = result.listCells(); //指定行、全部列族的全部列 // 遍历单元格 for (Cell cell : listCells) { System.out.println("列 族:" + Bytes.toString(CellUtil.cloneFamily(cell))); System.out.println("列 名:" + Bytes.toString(CellUtil.cloneQualifier(cell))); System.out.println("列 值:" + Bytes.toString(CellUtil.cloneValue(cell))); System.out.println("时间戳:" + cell.getTimestamp()); } } |
org.apache.hadoop.hbase.client.Get
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
Get(byte[] row) 构造函数(查询指定行)。Create a Get operation for the specified row. Get(Get get) Copy-constructor ------------------------- Get addColumn(byte[] family, byte[] qualifier) 获取指定列族和列修饰符对应的列。Get the column from the specific family with the specified qualifier. Get addFamily(byte[] family) 通过指定的列族获取其对应列的所有列。Get all columns from the specified family. int compareTo(Row other) xxx boolean equals(Object obj) xxx Set<byte[]> familySet() Method for retrieving the keys in the familyMap boolean getCacheBlocks() Get whether blocks should be cached for this Get. Map<byte[],NavigableSet<byte[]>> getFamilyMap() Method for retrieving the get's familyMap Map<String,Object> getFingerprint() Compile the table and column family (i.e. int getMaxResultsPerColumnFamily() Method for retrieving the get's maximum number of values to return per Column Family int getMaxVersions() Method for retrieving the get's maximum number of version byte[] getRow() Method for retrieving the get's row int getRowOffsetPerColumnFamily() Method for retrieving the get's offset per row per column family (#kvs to be skipped) TimeRange getTimeRange() Method for retrieving the get's TimeRange boolean hasFamilies() Method for checking if any families have been inserted into this Get int hashCode() xxx boolean isCheckExistenceOnly() xxx boolean isClosestRowBefore() xxx int numFamilies() Method for retrieving the number of families to get from Get setACL(Map<String,org.apache.hadoop.hbase.security.access.Permission> perms) xxx Get setACL(String user, org.apache.hadoop.hbase.security.access.Permission perms) xxx Get setAttribute(String name, byte[] value) Sets an attribute. Get setAuthorizations(org.apache.hadoop.hbase.security.visibility.Authorizations authorizations) Sets the authorizations to be used by this Query Get setCacheBlocks(boolean cacheBlocks) Set whether blocks should be cached for this Get. Get setCheckExistenceOnly(boolean checkExistenceOnly) xxx Get setClosestRowBefore(boolean closestRowBefore) xxx Get setConsistency(Consistency consistency) Sets the consistency level for this operation Get setFilter(Filter filter) 当执行Get操作时设置服务器端的过滤器。Apply the specified server-side filter when performing the Query. Get setId(String id) This method allows you to set an identifier on an operation. Get setIsolationLevel(IsolationLevel level) Set the isolation level for this query. Get setMaxResultsPerColumnFamily(int limit) Set the maximum number of values to return per row per Column Family Get setMaxVersions() Get all available versions. Get setMaxVersions(int maxVersions) Get up to the specified number of versions of each column. Get setReplicaId(int Id) Specify region replica id where Query will fetch data from. Get setRowOffsetPerColumnFamily(int offset) Set offset for the row per Column Family. Get setTimeRange(long minStamp, long maxStamp) 获取指定区间的列的版本号。Get versions of columns only within the specified timestamp range, [minStamp, maxStamp). Get setTimeStamp(long timestamp) Get versions of columns with the specified timestamp. Map<String,Object> toMap(int maxCols) Compile the details beyond the scope of getFingerprint (row, columns, timestamps, etc.) into a Map along with the fingerprinted information. |
org.apache.hadoop.hbase.client.Result
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
void addResults(org.apache.hadoop.hbase.protobuf.generated.ClientProtos.RegionLoadStats loadStats) Add load information about the region to the information about the result boolean advance() Advance the scanner 1 cell. protected int binarySearch(Cell[] kvs, byte[] family, byte[] qualifier) xxx protected int binarySearch(Cell[] kvs, byte[] family, int foffset, int flength, byte[] qualifier, int qoffset, int qlength) Searches for the latest value for the specified column. org.apache.hadoop.hbase.CellScanner cellScanner() xxx static void compareResults(Result res1, Result res2) Does a deep comparison of two Results, down to the byte arrays. boolean containsColumn(byte[] family, byte[] qualifier) 检查指定的列是否存在.Checks for existence of a value for the specified column (empty or not). boolean containsColumn(byte[] family, int foffset, int flength, byte[] qualifier, int qoffset, int qlength) Checks for existence of a value for the specified column (empty or not). boolean containsEmptyColumn(byte[] family, byte[] qualifier) Checks if the specified column contains an empty value (a zero-length byte array). boolean containsEmptyColumn(byte[] family, int foffset, int flength, byte[] qualifier, int qoffset, int qlength) Checks if the specified column contains an empty value (a zero-length byte array). boolean containsNonEmptyColumn(byte[] family, byte[] qualifier) Checks if the specified column contains a non-empty value (not a zero-length byte array). boolean containsNonEmptyColumn(byte[] family, int foffset, int flength, byte[] qualifier, int qoffset, int qlength) Checks if the specified column contains a non-empty value (not a zero-length byte array). void copyFrom(Result other) Copy another Result into this one. static Result create(Cell[] cells) Instantiate a Result with the specified array of KeyValues. static Result create(Cell[] cells, Boolean exists, boolean stale) xxx static Result create(List<Cell> cells) Instantiate a Result with the specified List of KeyValues. static Result create(List<Cell> cells, Boolean exists) xxx static Result create(List<Cell> cells, Boolean exists, boolean stale) xxx Cell current() xxx List<org.apache.hadoop.hbase.KeyValue> getColumn(byte[] family, byte[] qualifier) Deprecated.Use getColumnCells(byte[], byte[]) instead. List<Cell> getColumnCells(byte[] family, byte[] qualifier) Return the Cells for the specific column. org.apache.hadoop.hbase.KeyValue getColumnLatest(byte[] family, byte[] qualifier) Deprecated.Use getColumnLatestCell(byte[], byte[]) instead. org.apache.hadoop.hbase.KeyValue getColumnLatest(byte[] family, int foffset, int flength, byte[] qualifier, int qoffset, int qlength) Deprecated.Use getColumnLatestCell(byte[], int, int, byte[], int, int) instead. Cell getColumnLatestCell(byte[] family, byte[] qualifier) The Cell for the most recent timestamp for a given column. Cell getColumnLatestCell(byte[] family, int foffset, int flength, byte[] qualifier, int qoffset, int qlength) The Cell for the most recent timestamp for a given column. Boolean getExists() xxx NavigableMap<byte[],byte[]> getFamilyMap(byte[] family) 获取对应列族所包含的修饰符与值的键值对。Map of qualifiers to values. NavigableMap<byte[],NavigableMap<byte[],NavigableMap<Long,byte[]>>> getMap() Map of families to all versions of its qualifiers and values. NavigableMap<byte[],NavigableMap<byte[],byte[]>> getNoVersionMap() Map of families to their most recent qualifiers and values. byte[] getRow() Method for retrieving the row key that corresponds to the row from which this Result was created. org.apache.hadoop.hbase.protobuf.generated.ClientProtos.RegionLoadStats getStats() xxx static long getTotalSizeOfCells(Result result) Get total size of raw cells byte[] getValue(byte[] family, byte[] qualifier) 获取对应列的最新值。Get the latest version of the specified column. ByteBuffer getValueAsByteBuffer(byte[] family, byte[] qualifier) Returns the value wrapped in a new ByteBuffer. ByteBuffer getValueAsByteBuffer(byte[] family, int foffset, int flength, byte[] qualifier, int qoffset, int qlength) Returns the value wrapped in a new ByteBuffer. boolean isEmpty() Check if the underlying Cell [] is empty or not boolean isStale() Whether or not the results are coming from possibly stale data. List<org.apache.hadoop.hbase.KeyValue> list() Deprecated. as of 0.96, use listCells() List<Cell> listCells() Create a sorted list of the Cell's in this result. boolean loadValue(byte[] family, byte[] qualifier, ByteBuffer dst) Loads the latest version of the specified column into the provided ByteBuffer. boolean loadValue(byte[] family, int foffset, int flength, byte[] qualifier, int qoffset, int qlength, ByteBuffer dst) Loads the latest version of the specified column into the provided ByteBuffer. org.apache.hadoop.hbase.KeyValue[] raw() Deprecated.as of 0.96, use rawCells() Cell[] rawCells() Return the array of Cells backing this Result instance. void setExists(Boolean exists) xxx int size() xxx String toString() xxx byte[] value() Returns the value of the first column in the Result. |
4.扫描全部单元格
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
@Test public void testScan() throws IOException { String tableName = "tb1"; // 配置器 Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "localhost"); // 表实例 Connection connection = ConnectionFactory.createConnection(conf); Table table = connection.getTable(TableName.valueOf(tableName)); // 扫描器 ResultScanner resultScanner = table.getScanner(new Scan()); //针对全表的查询器 // 结果迭代器 //org.apache.hadoop.hbase.util.ConcatenatedLists.Iterator results = (org.apache.hadoop.hbase.util.ConcatenatedLists.Iterator) resultScanner.iterator(); //有警告,还是用下面的语句吧 java.util.Iterator<Result> results = resultScanner.iterator(); resultScanner.close(); // 关闭资源 while(results.hasNext()) { //Result result = (Result) results.next(); Result result = results.next(); List<Cell> cells = result.listCells(); for(Cell cell : cells) { System.out.println("列 族:" + Bytes.toString(CellUtil.cloneFamily(cell))); System.out.println("列 名:" + Bytes.toString(CellUtil.cloneQualifier(cell))); System.out.println("列 值:" + Bytes.toString(CellUtil.cloneValue(cell))); System.out.println("时间戳:" + cell.getTimestamp() + "\n------------------"); } } } |
org.apache.hadoop.hbase.client.ResultScanner
|
1 2 3 4 5 6 7 8 9 10 11 |
void close() 关闭扫描仪和释放任何已分配的资源。Closes the scanner and releases any resources it has allocated Result next() 下一条记录。Grab the next row's worth of values. Result[] next(int nbRows) xxx ------------- 继承自接口java.lang.Iterable的方法 ---------------- iterator 获取结果集的迭代器 |
5.删除单元格
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
@Test public void testDelete() throws IOException { String colFamily = "cf1"; String column = "col1"; String rowKey = "row1"; String tableName = "tb1"; // 配置器 Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "localhost"); // 表实例 Connection connection = ConnectionFactory.createConnection(conf); Table table = connection.getTable(TableName.valueOf(tableName)); // 删除器 Delete del = new Delete(Bytes.toBytes(rowKey)); // 操作指定行键的删除器 //del.deleteColumns(Bytes.toBytes(colFamily), Bytes.toBytes(column)); // 过时 del.addColumn(Bytes.toBytes(colFamily), Bytes.toBytes(column)); // 指定列族的列 table.delete(del); // 执行删除 System.out.println("删除操作完成"); } |
org.apache.hadoop.hbase.client.Delete
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
Delete(byte[] row) 构造函数(要删除的单元格所在的行)。Create a Delete operation for the specified row. Delete(byte[] rowArray, int rowOffset, int rowLength) Create a Delete operation for the specified row and timestamp. Delete(byte[] rowArray, int rowOffset, int rowLength, long ts) Create a Delete operation for the specified row and timestamp. Delete(byte[] row, long timestamp) Create a Delete operation for the specified row and timestamp. Delete(Delete d) xxx ----------------------------------------------------------- Delete addColumn(byte[] family, byte[] qualifier) 指定单元格所在的列族,列。Delete the latest version of the specified column. Delete addColumn(byte[] family, byte[] qualifier, long timestamp) Delete the specified version of the specified column. Delete addColumns(byte[] family, byte[] qualifier) Delete all versions of the specified column. Delete addColumns(byte[] family, byte[] qualifier, long timestamp) Delete all versions of the specified column with a timestamp less than or equal to the specified timestamp. Delete addDeleteMarker(Cell kv) Advanced use only. Delete addFamily(byte[] family) Delete all versions of all columns of the specified family. Delete addFamily(byte[] family, long timestamp) Delete all columns of the specified family with a timestamp less than or equal to the specified timestamp. Delete addFamilyVersion(byte[] family, long timestamp) Delete all columns of the specified family with a timestamp equal to the specified timestamp. Delete deleteColumn(byte[] family, byte[] qualifier) Deprecated. Since hbase-1.0.0. Use addColumn(byte[], byte[]) Delete deleteColumn(byte[] family, byte[] qualifier, long timestamp) Deprecated. Since hbase-1.0.0. Use addColumn(byte[], byte[], long) Delete deleteColumns(byte[] family, byte[] qualifier) Deprecated. Since hbase-1.0.0. Use addColumns(byte[], byte[]) Delete deleteColumns(byte[] family, byte[] qualifier, long timestamp) Deprecated. Since hbase-1.0.0. Use addColumns(byte[], byte[], long) Delete deleteFamily(byte[] family) Deprecated.Since 1.0.0. Use addFamily(byte[]) Delete deleteFamily(byte[] family, long timestamp) Deprecated.Since 1.0.0. Use addFamily(byte[], long) Delete deleteFamilyVersion(byte[] family, long timestamp) Deprecated.Since hbase-1.0.0. Use addFamilyVersion(byte[], long) Delete setACL(Map<String,org.apache.hadoop.hbase.security.access.Permission> perms) Delete setACL(String user, org.apache.hadoop.hbase.security.access.Permission perms) Delete setAttribute(String name, byte[] value) Sets an attribute. Delete setCellVisibility(org.apache.hadoop.hbase.security.visibility.CellVisibility expression) Sets the visibility expression associated with cells in this Mutation. Delete setClusterIds(List<UUID> clusterIds) Marks that the clusters with the given clusterIds have consumed the mutation Delete setDurability(Durability d) Set the durability for this mutation Delete setFamilyCellMap(NavigableMap<byte[],List<Cell>> map) Method for setting the put's familyMap Delete setFamilyMap(NavigableMap<byte[],List<org.apache.hadoop.hbase.KeyValue>> map) Deprecated. Delete setId(String id) This method allows you to set an identifier on an operation. Delete setTimestamp(long timestamp) Set the timestamp of the delete. Delete setTTL(long ttl) Set the TTL desired for the result of the mutation, in milliseconds. Delete setWriteToWAL(boolean write) Deprecated. Map<String,Object> toMap(int maxCols) Compile the details beyond the scope of getFingerprint (row, columns, timestamps, etc.) into a Map along with the fingerprinted information. |
6.删除行
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
@Test public void testDeleteAll() throws IOException { String tableName = "tb1"; String rowKey = "row1"; // 配置器 Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "localhost"); // 表实例 Connection connection = ConnectionFactory.createConnection(conf); Table table = connection.getTable(TableName.valueOf(tableName)); Delete deleteAll = new Delete(Bytes.toBytes(rowKey)); table.delete(deleteAll); System.out.println("删除整条记录操作结束"); } |
7.删除表
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
@Test public void deleteTable() throws IOException { String tableName = "tb1"; Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "localhost"); Connection connection = ConnectionFactory.createConnection(conf); Admin admin = connection.getAdmin(); // 首先,关闭表 admin.disableTable(TableName.valueOf(tableName)); // 然后,删除表 admin.deleteTable(TableName.valueOf(tableName)); System.out.println("删除表操作结束"); } |
四。HBase表结构参考图
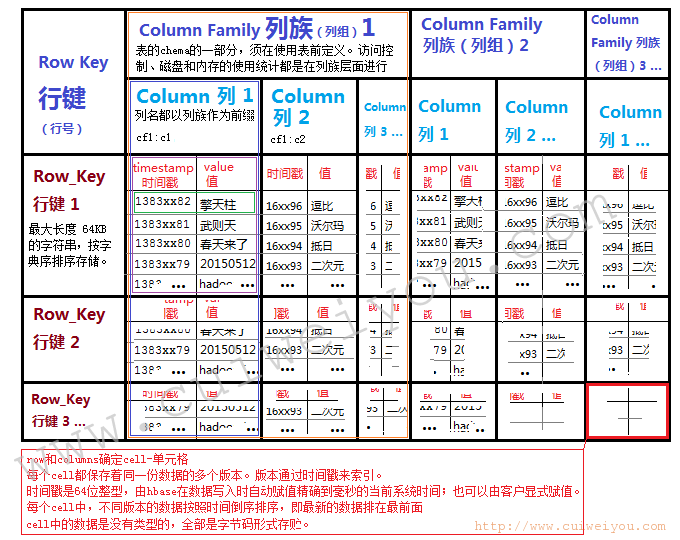
本文由崔维友 威格灵 cuiweiyou vigiles cuiweiyou 原创,转载请注明出处:http://www.gaohaiyan.com/1437.html
承接App定制、企业web站点、办公系统软件 设计开发,外包项目,毕设



