相关资源下载:
见 http://www.gaohaiyan.com/1355.html 篇尾
Oracle VM VirtualBox下载地址:
https://www.virtualbox.org/wiki/Downloads
ubuntu10.04x64下载地址:
http://download.chinaunix.net/down.php?id=31672&ResourceID=12776&site=6
OpenSSH,client、server、all下载地址:
http://archive.ubuntu.com/ubuntu/pool/main/o/openssh/
JDK下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/index.html
Hadoop下载地址:
http://www.apache.org/dyn/closer.cgi/hadoop/common/
在VirtualBox虚拟机软件中安装ubuntu系统,配置SSH、JDK、安置Hadoop程序,参考:
http://my.oschina.net/vigiles/blog/132244
Hadoop1.1.2集群配置参考:
http://my.oschina.net/vigiles/blog/132559
Hadoop2.3.0集群配置参考:
http://www.cnblogs.com/vigiles/p/3607145.html
http://my.oschina.net/vigiles/blog/208430
---------------------------------------------------------------------------------------------------------
本例说明:
ubuntu10.04x64主机共3台:
一台master主控机,配置为NameNode、SecondaryNameNode;
两台slave从属机, 配置为NodeManager、DataNode。
3台主机都在相同的路径下安装jdk-7u80-linux-x64、安置hadoop2.7.0程序、配置环境变量。
----------------------------------------------------------------------------------------------------------
一。主机设定
1.主机名、IP
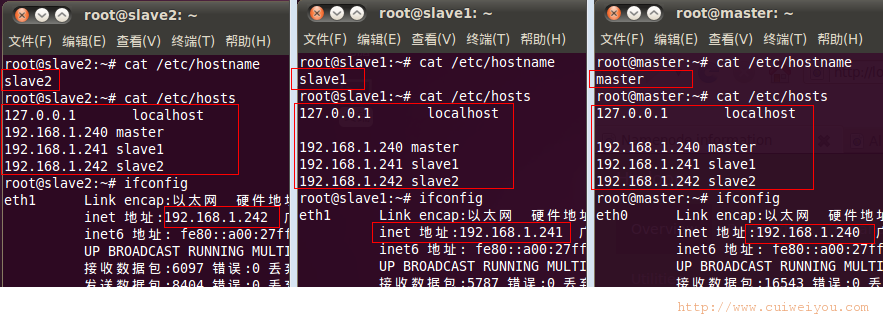
用到的命令语句:
gedit /etc/hostname
gedit /etc/hosts
gedit /etc/network/interfaces
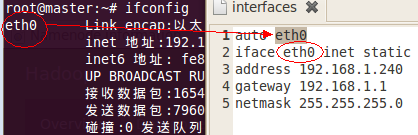
/etc/init.d/networking restart
2.环境变量
gedit /etc/profile
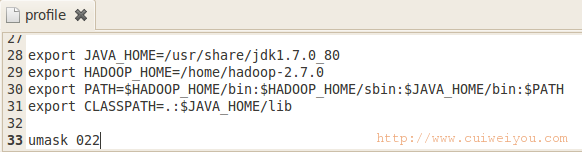
source /etc/profile
3.SSH
本例使用的文件:
openssh-client_5.3p1-3ubuntu3_amd64.deb
openssh-server_5.3p1-3ubuntu3_amd64.deb
ssh_5.3p1-3ubuntu3_all.deb
首先,在master上执行:
ssh-keygen
cp id_rsa.pub authorized_keys
scp authorized_keys root@slave1:/root/.ssh/
然后,在slave1上执行:
ssh-keygen
cat id_rsa.pub >> authorized_keys
scp authorized_keys root@slave2:/root/.ssh/
接着,在slave2上执行:
ssh-keygen
cat id_rsa.pub >> authorized_keys
最后,替换master和slave1上的密钥文件。最好先在master和slave上删除之。
scp -rpv authorized_keys root@slave1:/root/.ssh/
scp -rpv authorized_keys root@slave2:/root/.ssh/
可以 ssh 主机名 测试下,任意2台主机双向登录不要求密码即成功。
二。Hadoop配置
3台主机的hadoop配置是完全一样的。要配置的文件都在 %hadoop%/etc/hadoop/ 中。
1.core-site.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <!-- 指定集群HDFS系统中NameNode节点(master主控机)的IP地址和端口号 --> <name>fs.defaultFS</name> <value>hdfs://192.168.1.240:9000</value> </property> <property> <!-- 设置每个节点临时文件目录 --> <name>hadoop.tmp.dir</name> <!-- 当前用户须要对此目录有读写权限,启动集群时自动创建 --> <value>/home/hadoop-2.7.0/temp</value> </property> </configuration> |
2.hadoop-env.sh
约在25行,找到
|
1 2 3 |
export JAVA_HOME=${JAVA_HOME} |
在行首添加#注释,或直接修改为
|
1 2 3 |
export JAVA_HOME=/usr/share/jdk1.7.0_80 |
3.hdfs-site.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <!-- 指定SecondaryNamenode所在地址。本例设为和NN在同一个主机 --> <name>dfs.namenode.secondary.http-address</name> <value>192.168.1.240:9001</value> </property> <property> <!-- 指定NameNode的fsimage和edits元数据文件目录,须预先存在于NameNode节点上 --> <name>dfs.namenode.name.dir</name> <!-- 可以指定多个,用逗号隔开 --> <value>file:/home/hadoop-2.7.0/dfs-name</value> </property> <property> <!-- 指定DataNode节点中hdfs系统工作目录 --> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop-2.7.0/dfs-data</value> </property> <property> <!-- 文件块(副本)的备份数量 --> <name>dfs.replication</name> <!-- 要小于或等于附属机数量。默认3。本例只有2个slave节点 --> <value>2</value> </property> <property> <!-- 可以从网页端监控hdfs --> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration> |
4.mapred-site.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <!-- 指定map-reduce运算框架 --> <name>mapreduce.framework.name</name> <!-- 设定为yarn模式 --> <value>yarn</value> </property> </configuration> |
5.slaves
把全部slave从属机的主机名写入即可。
|
1 2 3 4 |
slave1 slave2 |
6.yarn-env.sh
约23行左右,找到
|
1 2 3 |
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/ |
修改为
|
1 2 3 |
export JAVA_HOME=/usr/share/jdk1.7.0_80 |
7.yarn-site.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
<?xml version="1.0"?> <configuration> <property> <!-- 指定RM所在的主机名 --> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <!-- 自定义一个yarn服务 --> <name>Yarn.nodemanager.aux-services</name> <!-- 启动Map-Reduce的shuffle功能。有地方说是 mapreduce_shuffle ,本例未验证 --> <value>mapreduce.shuffle</value> </property> <!-- 以下可以略 --> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>192.168.1.240:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>192.168.1.240:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>192.168.1.240:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>192.168.1.240:8033</value> </property> <!-- 这个可以留 --> <property> <name>yarn.resourcemanager.webapp.address</name> <value>192.168.1.240:8088</value> </property> </configuration> |
三。启动集群
以下都是在master主控机上执行的。
1.启动步骤
1)格式化HDFS系统
hdfs namenode -format
2)启动MRHDFS系统
start-dfs.sh
3)启动Yarn运算框架
start-yarn.sh
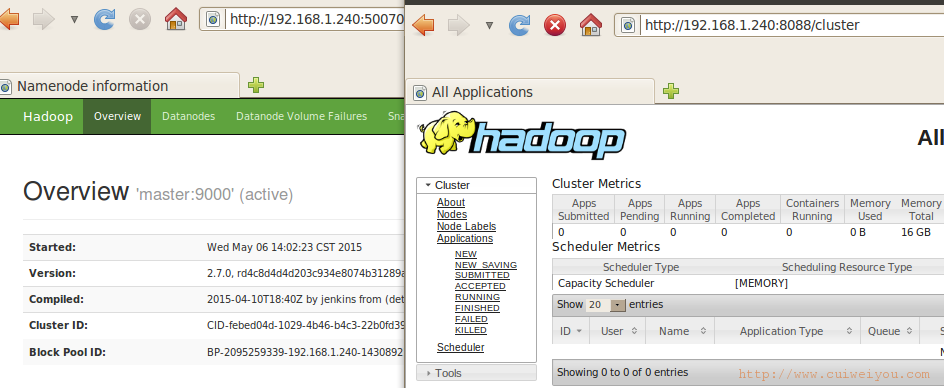
2.监控集群
1)hdfs dfsadmin -report
2)页面
http://192.168.1.240:50070 或 http://localhost:50070
http://192.168.1.240:8088/cluster 这个地址是在yarn-site.xml文件yarn.resourcemanager.webapp.address下配的。
-------------------------------------------------------------------------------------------------
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 |
################# master主控机启动记录 ################ #说明1.:首先格式化hdfs系统 root@master:~# hdfs namenode -format 15/05/06 14:01:40 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = master/192.168.1.240 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.7.0 #说明:这里遍历安装目录里的全部jar包 STARTUP_MSG: classpath = /home/hadoop-2.7.0/etc/hadoop:/home/hadoop-2.7.0/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r d4c8d4d4d203c934e8074b31289a28724c0842cf; compiled by 'jenkins' on 2015-04-10T18:40Z STARTUP_MSG: java = 1.7.0_80 ************************************************************/ 15/05/06 14:01:40 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 15/05/06 14:01:40 INFO namenode.NameNode: createNameNode [-format] #说明:网上的信息是说在32位系统安装64位hadoop或64位系统安装32位hadoop有此警告。但本例都64的情况下也出现了,没有找到合适的解释。本例中无碍 15/05/06 14:01:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Formatting using clusterid: CID-febed04d-1029-4b46-b4c3-22b0fd39aedd 15/05/06 14:01:47 INFO namenode.FSNamesystem: No KeyProvider found. 15/05/06 14:01:47 INFO namenode.FSNamesystem: fsLock is fair:true 15/05/06 14:01:47 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000 15/05/06 14:01:47 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 15/05/06 14:01:47 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 15/05/06 14:01:47 INFO blockmanagement.BlockManager: The block deletion will start around 2015 五月 06 14:01:47 15/05/06 14:01:47 INFO util.GSet: Computing capacity for map BlocksMap 15/05/06 14:01:47 INFO util.GSet: VM type = 64-bit 15/05/06 14:01:47 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB 15/05/06 14:01:47 INFO util.GSet: capacity = 2^21 = 2097152 entries 15/05/06 14:01:47 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 15/05/06 14:01:47 INFO blockmanagement.BlockManager: defaultReplication = 2 15/05/06 14:01:47 INFO blockmanagement.BlockManager: maxReplication = 512 15/05/06 14:01:47 INFO blockmanagement.BlockManager: minReplication = 1 15/05/06 14:01:47 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 15/05/06 14:01:47 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false 15/05/06 14:01:47 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 15/05/06 14:01:47 INFO blockmanagement.BlockManager: encryptDataTransfer = false 15/05/06 14:01:47 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 15/05/06 14:01:47 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE) 15/05/06 14:01:47 INFO namenode.FSNamesystem: supergroup = supergroup 15/05/06 14:01:47 INFO namenode.FSNamesystem: isPermissionEnabled = true 15/05/06 14:01:47 INFO namenode.FSNamesystem: HA Enabled: false 15/05/06 14:01:47 INFO namenode.FSNamesystem: Append Enabled: true 15/05/06 14:01:48 INFO util.GSet: Computing capacity for map INodeMap 15/05/06 14:01:48 INFO util.GSet: VM type = 64-bit 15/05/06 14:01:48 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB 15/05/06 14:01:48 INFO util.GSet: capacity = 2^20 = 1048576 entries 15/05/06 14:01:48 INFO namenode.FSDirectory: ACLs enabled? false 15/05/06 14:01:48 INFO namenode.FSDirectory: XAttrs enabled? true 15/05/06 14:01:48 INFO namenode.FSDirectory: Maximum size of an xattr: 16384 15/05/06 14:01:48 INFO namenode.NameNode: Caching file names occuring more than 10 times 15/05/06 14:01:48 INFO util.GSet: Computing capacity for map cachedBlocks 15/05/06 14:01:48 INFO util.GSet: VM type = 64-bit 15/05/06 14:01:48 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB 15/05/06 14:01:48 INFO util.GSet: capacity = 2^18 = 262144 entries 15/05/06 14:01:48 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 15/05/06 14:01:48 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0 15/05/06 14:01:48 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000 15/05/06 14:01:48 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 15/05/06 14:01:48 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 15/05/06 14:01:48 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 15/05/06 14:01:48 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 15/05/06 14:01:48 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 15/05/06 14:01:49 INFO util.GSet: Computing capacity for map NameNodeRetryCache 15/05/06 14:01:49 INFO util.GSet: VM type = 64-bit 15/05/06 14:01:49 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB 15/05/06 14:01:49 INFO util.GSet: capacity = 2^15 = 32768 entries 15/05/06 14:01:49 INFO namenode.FSImage: Allocated new BlockPoolId: BP-2095259339-192.168.1.240-1430892109180 15/05/06 14:01:49 INFO common.Storage: Storage directory /home/hadoop-2.7.0/dfs-name has been successfully formatted. 15/05/06 14:01:49 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 15/05/06 14:01:49 INFO util.ExitUtil: Exiting with status 0 15/05/06 14:01:49 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at master/192.168.1.240 ************************************************************/ #说明2.:启动文件系统。2.7.0版不再推荐start-all.sh命令。 root@master:~# start-dfs.sh 15/05/06 14:02:06 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [master] master: starting namenode, logging to /home/hadoop-2.7.0/logs/hadoop-root-namenode-master.out slave2: starting datanode, logging to /home/hadoop-2.7.0/logs/hadoop-root-datanode-slave2.out slave1: starting datanode, logging to /home/hadoop-2.7.0/logs/hadoop-root-datanode-slave1.out Starting secondary namenodes [master] master: starting secondarynamenode, logging to /home/hadoop-2.7.0/logs/hadoop-root-secondarynamenode-master.out 15/05/06 14:02:52 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable #说明:此时master主控机上启动了NN和SNN。而slave从属机上启动了DataNode root@master:~# jps 1943 Jps 1560 NameNode 1808 SecondaryNameNode #说明3.:启动yarn计算框架 root@master:~# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /home/hadoop-2.7.0/logs/yarn-root-resourcemanager-master.out slave2: starting nodemanager, logging to /home/hadoop-2.7.0/logs/yarn-root-nodemanager-slave2.out slave1: starting nodemanager, logging to /home/hadoop-2.7.0/logs/yarn-root-nodemanager-slave1.out #说明:此时master上启动NN、SNN、和RM,而slave上启动了DN、NodeManager root@master:~# jps 1560 NameNode 2071 Jps 1993 ResourceManager 1808 SecondaryNameNode #说明4.:查看各节点简报 root@master:~# hdfs dfsadmin -report 15/05/06 14:04:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable #说明:总述整个集群的信息 Configured Capacity: 12023971840 (11.20 GB) Present Capacity: 3729260544 (3.47 GB) DFS Remaining: 3729211392 (3.47 GB) DFS Used: 49152 (48 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ------------------------------------------------- #说明:分别描述各个slave节点 Live datanodes (2): Name: 192.168.1.242:50010 (slave2) Hostname: slave2 Decommission Status : Normal Configured Capacity: 6011985920 (5.60 GB) DFS Used: 24576 (24 KB) Non DFS Used: 4147228672 (3.86 GB) DFS Remaining: 1864732672 (1.74 GB) DFS Used%: 0.00% DFS Remaining%: 31.02% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Wed May 06 14:04:29 CST 2015 Name: 192.168.1.241:50010 (slave1) Hostname: slave1 Decommission Status : Normal Configured Capacity: 6011985920 (5.60 GB) DFS Used: 24576 (24 KB) Non DFS Used: 4147482624 (3.86 GB) DFS Remaining: 1864478720 (1.74 GB) DFS Used%: 0.00% DFS Remaining%: 31.01% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Wed May 06 14:04:29 CST 2015 root@master:~# |

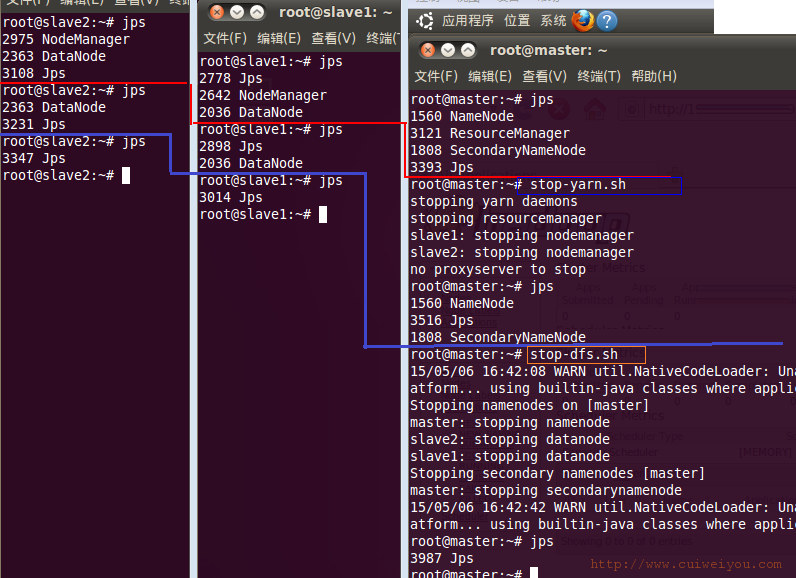
3.停止集群
1.stop-yarn.sh
2.stop-dfs.sh
本文由崔维友 威格灵 cuiweiyou vigiles cuiweiyou 原创,转载请注明出处:http://www.gaohaiyan.com/1379.html
承接App定制、企业web站点、办公系统软件 设计开发,外包项目,毕设



