准备一个数据集,基于老妹相亲已经掌握的15个小伙的信息,进行整理得到。
每个人有5项信息,前4项是基本情况——特征,第5项是老妹根据前4项做出的决定——即这个人的标签。
这些信息组成一个二维序列(二维数组、表),每行代表1个人,每列表示同一种特征。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
def createDataMat(): # 已知15个人的数据,前4列特征是条件,最后一列的标签是结果 # 第1列,年龄:0青, 1中,2老; # 第2列,工作:0一般,1好; # 第3列,房子:0没有,1有; # 第4列,车子:0一般,1好,2很好; # 第5列,人物标签:no代表不考虑相亲,yes代表考虑相亲。 dataMat = [[0, 0, 0, 0, 'no'], [0, 0, 0, 1, 'no'], [0, 1, 0, 1, 'yes'], [0, 1, 1, 0, 'yes'], [0, 0, 0, 0, 'no'], [1, 0, 0, 0, 'no'], [1, 0, 0, 1, 'no'], [1, 1, 1, 1, 'yes'], [1, 0, 1, 2, 'yes'], [1, 0, 1, 2, 'yes'], [2, 0, 1, 2, 'yes'], [2, 0, 1, 1, 'yes'], [2, 1, 0, 1, 'yes'], [2, 1, 0, 2, 'yes'], [2, 0, 0, 0, 'no']] featureList = ['年龄', '工作', '房子', '车子'] # 特征名称 return dataMat, featureList |
1.经验熵
这一份数据中,最后一列,是老妹想要得到的结果,无论前面考虑多少种“特征”,无非是为了最终相亲与否的“标签”,
我们用一个数字来表示老妹想得到这个标签的程度的话,这个数字称为“熵”,称为“经验熵(香农熵)”。
要计算经验熵,标签这一列出现的2个值‘yes’和‘no’,分别有多少比例,然后结合数学中的log运算,进行计算。
(1)已知数据的标签有2种:no、yes,no有9个,yes有6个,
no个数在总人数的比例 probNo = 9/15
yes个数在总人数的比例 probYes = 6/15
(2)此数据集基于标签的经验熵HD即:
HD = ( -1 * probYes * log(2)probYes ) + ( -1 * probNo * log(2)probNo )
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import math def getShannonEntropy(dataMat): # 计算“人物标签”的 经验熵(香农熵) # 1.统计每个标签出现的次数 labelAmount = {} # 计数器 for featureList in dataMat: # 遍历每个人 label = featureList[-1] # 提取人物标签 if label not in labelAmount.keys(): labelAmount[label] = 0 labelAmount[label] += 1 # 标签次数累加 personCount = len(dataMat) # 人数 # 2.求香农熵 entropy = 0.0 # 经验熵(香农熵) for key in labelAmount: # 遍历标签 prob = float(labelAmount[key]) / personCount # [1]标签(Label)的概率 = 标签次数 / 人数。 gol = math.log(prob, 2) # [2]以2为底概率的对数。2的gol次方等于prob。 ent = prob * gol # [3]计算香农熵 = 概率 * 以2为底概率的对数。 entropy -= ent # [4]累减 return entropy |
2.信息增益
既然有4个考虑因素(特征)来决定最终标签值是yes还是no,那么是不是有某个特征的会起决定性的作用?通常是的。
本例中"房子"一项似乎对结果影响很大,

特征对标签的影响有多大,也用数字来表示,称为“信息增益”。
要计算信息增益,得考虑数据集中人数、本特征的每种值的比例,对应的每种标签值的比例,还要结合经验熵。
比如先计算‘年龄’特征的信息增益,
(1)年龄为0的5人中,标签为no的3个,yes的2个,比例分别是 3/5 、2/5,
则,这5人数据的经验熵为 HDAge0 = (-1 * 3/5 * math.log(3/5, 2)) + (-1 * 2/5 * math.log(2/5, 2))
(2)年龄为1的5人中,标签为no的2个,yes的3个,比例分别是 2/5 、3/5,
则,这5人数据的经验熵为 HDAge1 = (-1 * 2/5 * math.log(2/5, 2)) + (-1 * 3/5 * math.log(3/5, 2))
(3)年龄为2的5人中,标签为no的1个,yes的4个,比例分别是 1/5 、4/5,
则,这5人数据的经验熵为 HDAge2 = (-1 * 1/5 * math.log(1/5, 2)) + (-1 * 4/5 * math.log(4/5, 2))
(4)总人数中,
年龄为0的5个人占比ratioAge0 = 5/15、
年龄为1的5个人占比ratioAge1 = 5/15、
年龄为2的5个人占比ratioAge2 = 5/15、
(5)则特征年龄的“经验条件熵”HAage即
HAage = ratioAge0 * HDAge0 + ratioAge1 * HDAge1 + ratioAge2 * HDAge2
(6)年龄的信息增益gDAage为 数据集经验熵HD 减去 年龄的经验条件熵HAage 。
gDAage = HD - HAage
如此,再计算工作、房子、车子的信息增益:gDAjob、gDAhouse、gDAcredit。只要看一下哪个特征的信息增益最大,就知道哪个特征起作用最大。
即特征的信息增益表现了在预测最终标签值时的优先级;信息增益越大,则此特征越能决定标签为何值。
如下代码演示计算信息增益:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
def sievingData(dataMat, axis, value): # 按照特征值过滤人员 """ dataMat 总数据集 axis 进行筛选的特征的列 value 标准特征值 """ sievingMat = [] # 创建返回的数据集列表 for featureList in dataMat: # 遍历每个人 if featureList[axis] == value: # 如果这个人的这个特征符合这个值, reducedFeatVec = featureList[:axis] # 保存此列前的特征,过滤axis特征 reducedFeatVec.extend(featureList[axis+1:]) # 保存此列后的特征 sievingMat.append(reducedFeatVec) # 就把这个人的其它特征保存起来 # axis这一列特征舍弃 return sievingMat # 返回删除这列特征、且符合此特征的人员数据集 def getInfoGainMap(dataMat): # 计算每列特征的信息增益 infoGainMap = {} baseEntropy = getShannonEntropy(dataMat) # 【1】计算总数据集的香农熵 featureAmount = len(dataMat[0]) - 1 # 每个人的(不包括人物标签)特征数量 for i in range(featureAmount): # 【2】遍历每个特征 featureColumn = [person[i] for person in dataMat] # 按列取全部人的特征:年龄/工作/房子/车子 uniqueFeatureValues = set(featureColumn) # list转set集合{},去重。【3】得到这个特征出现过的全部的值 experienceEntropy = 0.0 # 这列的经验条件熵 for value in uniqueFeatureValues: # 【4】遍历这个特征的值 partDataMat = sievingData(dataMat, i, value) # 1)返回符合此特征的人。这些人的这个特征都是这个值 partEntropy = getShannonEntropy(partDataMat) # 2)这部分人的香农熵。 prob = len(partDataMat) / float(len(dataMat)) # 3)这部分人在总人数的比例 experienceEntropy += prob * partEntropy # 4)计算【经验条件熵】 infoGain = baseEntropy - experienceEntropy # 【5】计算信息增益 infoGainMap.update({i: infoGain}) return infoGainMap def getBestInfoGainFeatureIndex(infoGainMap): # 取信息增益最大的特征的索引值 bestFeatureIndex = 0 bestFeatureGain = 0.0 indexs = list(infoGainMap.keys()) for featureIndex in indexs: value = infoGainMap[featureIndex] # print(featureIndex, value) if (value > bestFeatureGain): # 计算信息增益 bestFeatureGain = value # 最大的信息增益 bestFeatureIndex = featureIndex # 信息增益最大的特征的索引值 return bestFeatureIndex |

3.决策树
要把特征对标签的影响能力表现出来,根据它们的信息增益用树结构可以很清晰直白的做到。树结构表达了什么因素导致什么决策,称为决策树。
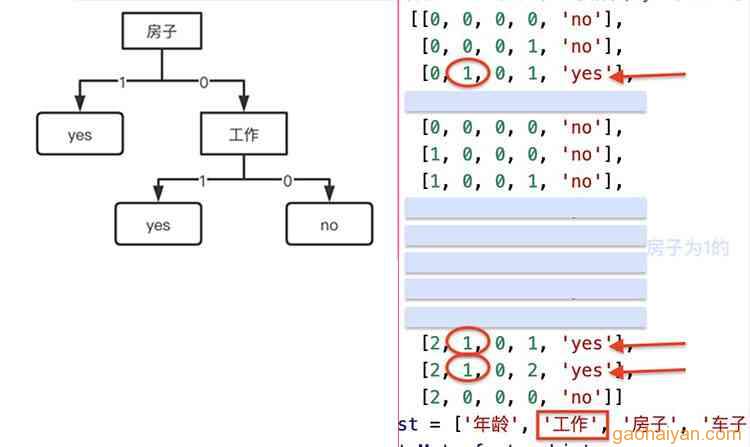 从图中可以看出,除了房子、工作两个特征,可以导致标签出现“yes”,年龄、车子无论什么值,标签都是‘no’。而决策树保留的也是和‘yes’相关的、有用的特征。
从图中可以看出,除了房子、工作两个特征,可以导致标签出现“yes”,年龄、车子无论什么值,标签都是‘no’。而决策树保留的也是和‘yes’相关的、有用的特征。
● 房子是信息增益最大的特征,作为整棵树的根节点。即为树结构的第1层。
房子为1时,检查标签都为yes。则直接指向"yes"这个“叶子节点”;为树结构的第2层。
房子为0时,标签有yes也有no。那么,须对[年龄、工作、车子]3个特征重新计算出信息增益最大的,作为第2层的另一个节点(下一层的根节点)。
● 特征节点是否有分支,就看它的值对应的标签的值。
无论特征值是0/1/2,只要对应标签值是同一个,则直接指向对应“叶子节点”,结束。
对应标签值不止1个,则下一轮计算。
这种计算方法称为 ID3算法 。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
def getMyTree(dataMat, featureList): """计算最优信息增益 Args: dataMat : 本次处理的人物集,每人n个特征和1个标签 featureList : 特征名称序列 """ # 1.判断是不是 叶子节点 person = dataMat[0] if len(person) == 1: # 人员数据只剩1列了,即人物标签列,要么yes要么no。 print("分支结束", person[-1]) return person[-1] labelColumn = [person[-1] for person in dataMat] # 人物标签列 全部的值 feature = labelColumn[0] # yes或者no if labelColumn.count(feature) == len(labelColumn): # 这个值的数量和全部的标签数量相同 print("分支结束", labelColumn[0]) return labelColumn[0] # 2.创建 节点 infoGainMap = getInfoGainMap(dataMat) bestFeatureIndex = getBestInfoGainFeatureIndex(infoGainMap) bestFeature = featureList[bestFeatureIndex] print("最优特征", bestFeature) node = {bestFeature:{}} del(featureList[bestFeatureIndex]) # 防止分支读取特征名错误 # 3.分支有哪几个 bestFeatureColumn = [person[bestFeatureIndex] for person in dataMat] # 当前数据集中全部的最优特征的值 uniqueBestFeatureValues = list(set(bestFeatureColumn)) # 去掉重复的属性值 uniqueBestFeatureValues = sorted(uniqueBestFeatureValues, reverse=True) print("最优特征有哪些值", uniqueBestFeatureValues) # 4.创建 分支 for value in uniqueBestFeatureValues: # 遍历最优特征的值 sievingMat = sievingData(dataMat, bestFeatureIndex, value) # 返回符合此特征,且舍弃此特征列的人员。即计算其它特征 nodeValue = getMyTree(sievingMat, featureList) # 计算分支 node.get(bestFeature).update({value:nodeValue}) # 保存子分支 return node if __name__ == '__main__': dataMat, featureList = createDataMat() tree = getMyTree(dataMat, featureList) print(tree) |
|
1 2 3 4 5 6 7 8 9 10 |
$ 最优特征 房子 最优特征有哪些值 [1, 0] 值: 1 ,分支结束 yes 最优特征 工作 最优特征有哪些值 [1, 0] 值: 1 ,分支结束 yes 值: 0 ,分支结束 no {'房子': {1: 'yes', 0: {'工作': {1: 'yes', 0: 'no'}}}} $ |
4.可视化
高级绘图诸如matplotlib、pyEcharts等。
这里使用python内置的turtle,针对本例的决策树进行绘制,代码没有通用性。
上面得到的决策树json,即二叉树结构。可以对其解析为一个类链表进行存储,能通过父子节点关系以确定绘制位置。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
import turtle class Node: def __init__(self): self.name = '' # 节点名 self.isYes = False # true为1,false为0。表明连线的文本 self.x = 300 # 位置 self.y = 10 # 位置 self.r = 30 # 半径 self.parent = None # 父节点 self.children_yes = None # 子节点 self.children_no = None # 子节点 def __drawNode(self): # 画节点 turtle.penup() turtle.goto(self.x, self.y) turtle.pendown() turtle.circle(self.r) turtle.penup() turtle.goto(self.x, self.y + self.r) turtle.write(self.name) def __drawLine(self): # 画连线 turtle.penup() parent_y = self.parent.y + self.parent.r * 2 # 父节点y turtle.goto(self.parent.x, parent_y) turtle.pendown() turtle.goto(self.x, self.y) turtle.penup() turtle.goto(abs(self.x + self.parent.x) / 2, abs(self.y + parent_y) / 2) if self.isYes: turtle.write("1") else: turtle.write("0") def draw(self): if self.parent is not None: # 有父节点,就先画连线 self.__drawLine() self.__drawNode() # 本节点 if self.children_yes is not None: # 下一级绘制 self.children_yes.draw() if self.children_no is not None: # 下一级绘制 self.children_no.draw() def getNode(tree, parentNode=None, _isYes=False): node = Node() node.parent = parentNode if parentNode: # 如果有父节点,则相对的设置本节点位置 node.isYes = _isYes # 本节点指向yes,还是no if node.isYes: # 如果本节点指向yes,则位置x向左移 node.x = parentNode.x - parentNode.r*2 else: # 如果本节点指向no,则位置x向右移 node.x = parentNode.x + parentNode.r*2 node.y = parentNode.y + parentNode.r*3 # 位置y if isinstance(tree, str): # 如果本节点是字符串,则分支结束 node.name = tree return node for k, v in tree.items(): # 解析下一层的字典。 node.name = k node.children_yes = getNode(v[1], node, True) # 取第1个元素,即key为1的 node.children_yes.isYes = True node.children_no = getNode(v[0], node, False) # 取第2个元素,即key为0的 return node def drawTree(json): turtle.mode("world") turtle.screensize(600, 600) turtle.setworldcoordinates(0, 600, 600, 0) turtle.speed(0) turtle.hideturtle() turtle.penup() node = getNode(json) node.draw() turtle.mainloop() if __name__ == '__main__': dataMat, featureList = createDataMat() tree = getMyTree(dataMat, featureList) drawTree(tree) |

5.预测
首先修改一下getMyTree函数,以保存最终有用/有效的特征名称。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
def getMyTree(dataMat, featureList, bestFeatureList): """ bestFeatureList : 存储有效的最优特征 """ # 1. person = dataMat[0] if len(person) == 1: return person[-1] labelColumn = [person[-1] for person in dataMat] feature = labelColumn[0] if labelColumn.count(feature) == len(labelColumn): return labelColumn[0] # 2. infoGainMap = getInfoGainMap(dataMat) bestFeatureIndex = getBestInfoGainFeatureIndex(infoGainMap) bestFeature = featureList[bestFeatureIndex] bestFeatureList.append(bestFeature) # 存储最优特征 node = {bestFeature:{}} del(featureList[bestFeatureIndex]) # 3. bestFeatureColumn = [person[bestFeatureIndex] for person in dataMat] uniqueBestFeatureValues = list(set(bestFeatureColumn)) uniqueBestFeatureValues = sorted(uniqueBestFeatureValues, reverse=True) # 4. for value in uniqueBestFeatureValues: sievingMat = sievingData(dataMat, bestFeatureIndex, value) nodeValue = getMyTree(sievingMat, featureList, bestFeatureList) # 继续存储 node.get(bestFeature).update({value:nodeValue}) return node if __name__ == '__main__': dataMat, featureList = createDataMat() bestFeatureList = [] # 存储有用的特征名称 tree = getMyTree(dataMat, featureList, bestFeatureList) print(tree) print(bestFeatureList) |
|
1 2 3 4 |
$ {'房子': {1: 'yes', 0: {'工作': {1: 'yes', 0: 'no'}}}} ['房子', '工作'] $ |
这里生成的决策树“tree”,即通常所说的“模型”,一旦生成后就可重复使用。
在进行预测时,只要按照模型中 有用特征 的顺序,定义测试数据,代入模型即可。
如 [0, 1] 表示没有房子,但工作挺好。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
def predict(model, bestFeatureList, testData): # 预测 """ model ([type]): 模型 bestFeatureList ([type]): 有效特征序列 testData ([type]): 测试数据 """ condition = next(iter(model)) # 获取字典决策树的节点 index = bestFeatureList.index(condition) # 节点在有用特征序列的索引 testEle = testData[index] # 测试数据和模型数据的顺序一致,取测试数据对应特征元素 tcid = model[condition] # 下一级字典 for key in tcid.keys(): # key即匹配值1或0 if testEle == key: v = tcid[key] # 匹配到的结果 if isinstance(v, dict): matche = predict(tcid[key], bestFeatureList, testData) else: matche = tcid[key] # 预测结果 return matche if __name__ == '__main__': dataMat, featureList = createDataMat() bestFeatureList = [] # 存储有用的特征名称 tree = getMyTree(dataMat, featureList, bestFeatureList) print("有用特征", bestFeatureList) testData = [0, 1] # 没有房子,但有个好工作 print("预测特征", testData) matche = predict(tree, bestFeatureList, testData) if 'yes' == matche: print("预测结果", "相亲") else : print("预测结果", "不相亲") |
|
1 2 3 4 5 |
$ 有用特征 ['房子', '工作'] 预测特征 [0, 1] 预测结果 相亲 $ |
6.模型持久化
上面说了,模型一旦生成,以后就直接使用,当业务调整、算法优化、数据集足够扩充,则有必要进行重新构建。
持久化就是写到硬盘上,保存为一个文件,这样也好分享给别人使用。可保存为txt文件、数据库文件、等等,通常以二进制的形式保存,不希望公开的话还会加密。
本例使用pickle包进行持久化:
|
1 2 3 4 5 6 7 8 9 10 11 |
if __name__ == '__main__': dataMat, featureList = createDataMat() bestFeatureList = [] tree = getMyTree(dataMat, featureList, bestFeatureList) # 根据需要加密原始数据 import pickle with open("mytree.m", "wb") as f: # 序列化为2进制数据,写入到文件。后缀自定义 pickle.dump(tree, f) # 1条 pickle.dump(bestFeatureList, f) # 2条 |
把这个"mytree.m"文件发给老妹,让她自己用。她的代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
def predict(model, bestFeatureList, testData): condition = next(iter(model)) index = bestFeatureList.index(condition) testEle = testData[index] tcid = model[condition] for key in tcid.keys(): if testEle == key: v = tcid[key] if isinstance(v, dict): matche = predict(tcid[key], bestFeatureList, testData) else: matche = tcid[key] return matche def getModel(): # 加载模型 import pickle data=[] file = open("mytree.m", "rb") # 模型文件。已知2行数据 while 1: try: p = pickle.load(file)# 从文件反序列化 # 根据需要进行解密 data.append(p) except : break file.close() model = data[0] bestFeatureList=data[1] return model, bestFeatureList if __name__ == '__main__': testData = [0, 0] # test data model, bestFeatureList = getModel() # 加载模型 matche = predict(model, bestFeatureList, testData) if 'yes' == matche: print("预测结果", "相亲") else : print("预测结果", "不相亲") |
本文参考 https://cuijiahua.com/blog/2017/11/ml_2_decision_tree_1.html
- end
本文由崔维友 威格灵 cuiweiyou vigiles cuiweiyou 原创,转载请注明出处:http://www.gaohaiyan.com/3497.html
承接App定制、企业web站点、办公系统软件 设计开发,外包项目,毕设



