一。XML入门
可扩展标记语言,用于描述关系型数据。xml文件为xml后缀的文本文件。
1. 语法:
使用配对的尖括号及问号包裹xml关键字。
1)声明:使用version设置版本
<?xml version="1.0" ?>
2)编码:使用encoding设置字符集编码。同时文件保存时使用相同编码
<?xml version="1.0" encoding="utf-8" ?>
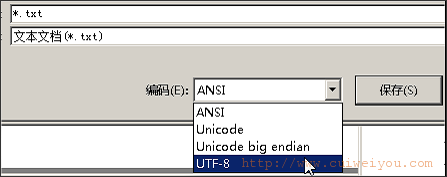
3)独立声明:使用standalone设置是否使用约束文件
当没有此参数时,默认为yes-独立存在;设置为no指不可独立存在,必须指明约束文件。
<?xml version="1.0" encoding="gb2312" standalone="yes" ?>
4)元素:
xml文件中,包含唯一一个根元素,以及若干子元素,每个子元素可以包含下一级若干子元素。每个子元素都可以包含若干属性。
(1)元素命名规范:
(1)区分大小写。
(2)不能以数字或"_" (下划)或xml开头。
(3)中间不能包含冒号(:)、不能包含空格。
(2)元素属性
(1)属性值一定要用双引号(“)或单引号(‘)引起来。
(2)定义属性必须遵循与元素相同的命名规范 (全用英文)。
2. 注释:
1)格式:
<!-- 注释体 -->
2)注意:
XML声明之前不能有注释。
注释不能嵌套,且注释体中不宜出现--。
3)示例:
(1)样板:/h4>
123456789101112131415
<?xml version="1.0" ?> <根元素> <一级子元素> <二级子元素 属性="值">元素体</二级子元素> <二级子元素 属性="值">元素体</二级子元素> <二级子元素 属性="值">元素体</二级子元素> </一级子元素> <一级子元素> <二级子元素>元素体</二级子元素> <二级子元素>元素体</二级子元素> <二级子元素>元素体</二级子元素> </一级子元素></根元素>
(2)实例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<?xml version="1.0" ?> <根元素> <一级子元素> <二级子元素 属性="值">元素体</二级子元素> <二级子元素 属性="值">元素体</二级子元素> <二级子元素 属性="值">元素体</二级子元素> </一级子元素> <一级子元素> <二级子元素>元素体</二级子元素> <二级子元素>元素体</二级子元素> <二级子元素>元素体</二级子元素> </一级子元素> </根元素> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<?xml version="1.0" ?> <!-- 这是一个xml示例文件 --> <书架> <书> <书名>Java就业培训教程</书名> <作者>vigiles</作者> <售价>39.00元</售价> </书> <书> <书名>JavaScript网页开发</书名> <作者>威格灵</作者> <售价>28.00元</售价> </书> </书架> |
3. 代码块:
<![CDATA[ 代码块 ]]> 。说明其中的代码块内容为普通文本,一般为了在网页中展示编程代码使用。
语法:
|
1 2 3 4 5 6 |
<![CDATA[ [crayon-6813531ba9bb6590524401 ] <lang>Java</lang> <user>vigiles</user> |
]]>
[/crayon]
4. 转义字符:
空格等特殊字符在解析时可能会被浏览器过滤掉而不能达到我们的理想效果,因此我们使用转义字符代替它们。
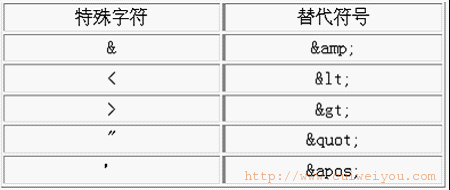
示例:
|
1 2 3 4 5 6 7 8 9 10 |
<?xml version="1.0" encoding="utf-8" ?> <!-- 保存为utf-8编码的xml文件 --> <书架> <书> <书名>< < Java就业培训教程 > ></书名> <作者>崔 维 友</作者> </书> </书架> |
二。DTD约束
dtd文档类型定义文件是xml的约束文件。单独的dtd文件必须以utf-8编码保存。dtd约束的使用分为外部约束和内部约束。
1. 引入外部dtd文件:
即创建一个dtd文件,然后在xml文件中引入。
1)xml引入语法:
(1)使用本地dtd文件:
<!DOCUMENT 根节点 SYSTEM "test.dtd">
(2)使用网络dtd文件:
<!DOCTYPE 根结点 PUBLIC "DTD名称" "DTD文件的URL">
如:
|
1 2 3 4 5 |
<!DOCTYPE web-app PUBLIC "-//Sun//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd"> |
2)dtd文件语法:
|
1 2 3 4 5 6 |
<!ELEMENT 根节点 (子节点1, 子节点2, 子节点3)> <!ELEMENT 子节点1 (#数据类型)> <!ELEMENT 子节点2 (#数据类型)> <!ELEMENT 子节点3 (#数据类型)> |
2.使用内部dtd约束:
将dtd约束内容直接写入xml文件中。
语法:
|
1 2 3 4 5 6 7 8 9 |
<?xml version="1.0" encoding="utf-8" ?> <!DOCUMENT 书架 [ 约束体 ]> <书架> 元素体 </书架> |
3. dtd语法:
1)声明xml文件中的元素:使用element关键字
(1)复杂元素:带有子元素
<!ELEMENT 元素名称 (子元素1, 子元素2, 子元素3)>
1》子元素的数量限制:
①子元素1最少出现一次:使用加号+标注
<!ELEMENT 元素名称 (子元素1+, 子元素2, 子元素3)>
②子元素1最多出现一次:使用问号?标注
<!ELEMENT 元素名称 (子元素1?, 子元素2, 子元素3)>
③子元素1出现任意:使用星号*标注
<!ELEMENT 元素名称 (子元素1*, 子元素2, 子元素3)>
④没有标注加号、问号、星号表示必须出现且只出现一次
2》子元素的序列限制:
①逗号限定了元素出现的先后顺序
②竖线|表示选择出现元素:
如:必须出现元素1;然后元素2或者元素3出现一个,并且至少出现一次
<!ELEMENT 元素名称 (子元素1, (子元素2 | 子元素3)+)>
(2)简单元素
<!ELEMENT 元素名称 元素类型>
元素类型包括:
① <!ELEMENT 元素名称 (#PCDATA)>
PCDATA:被解析器解析的文本字符串
② <!ELEMENT 元素名称 (#CDATA)>
CDATA:不会被解析器解析的文本字符串
③ <!ELEMENT 元素名称 EMPTY>
EMPTY:空内容,不得填写任何元素体
④ <!ELEMENT 元素名称 ANY>
ANY:任意内容
2)声明元素的属性:使用attlist关键字
(1)语法:
<!ATTLIST 已有元素名称 自定义属性名称 属性类型 默认值>
(2)属性类型:
①CDATA: 值为字符数据
②(att1| att2|..): 值为枚举列表中的一个值
③ID: 值为唯一的id
④IDREF: 值为另外一个元素的id
⑤IDREFS: 值为其他id的列表
⑥NMTOKEN: 值为合法的XML名称
⑦NMTOKENS: 值为合法的XML名称的列表
⑧ENTITY: 值为一个实体
⑨ENTITIES: 值为一个实体列表
⑩NOTATION: 值为符号的名称
xml: 值为一个预定义的XML值
(3)默认值:
①#REQUIRED: 属性值是必需的
②#IMPLIED: 属性值非必需的
③#FIXED "value": 属性值是固定的
3)声明实体:
用于定义引用普通文本或特殊字符的快捷方式的变量,提高字段的复用性。
(1)引用实体:在dtd文件中定义,在xml文件中使用
语法:
dtd文件:<!ENTITY 实体名称 "实体的值">
xml文件:<元素>&实体名称;</元素>
(2)参数实体:在dtd中定义,在dtd中使用
语法:
创建:<!ENTITY %实体名称 "值1 | 值2 | 值3">
使用:<!ELEMENT 元素名 (%实体名称)+>
三。Schema约束
XML Schema模式文档比dtd更加符合XML语法结构,其本身就是一个xml文件,扩展名通常为.xsd。Schema对名称空间支持得非常好,很容易被XML 解析器解析,比XML DTD支持更多的数据类型,并支持用户自定义新的数据类型。
XML Schema文档也必须有一个根结点,这个根结点的名称为Schema。
XML Schema文档声明的元素通常绑定到一个名称空间(uri)上,以后XML文件就可以通过这个URI来告诉解析引擎,xml文档中编写的元素来自哪里,被谁约束。uri虽然是以http://开头,但是它可以不指向任何一个真实的地址,而仅仅是作为一个名称空间来声明。
1.引入xsd文件:
使用xmlns关键字在xml文件中引入schema约束:
|
1 2 3 4 5 6 7 8 9 10 11 |
<?xml version="1.0"?> <名称空间:根元素 xmlns:名称空间="http://指定的uriA" xmlns:辅助名称空间="http://指定的uriB" 辅助名称空间:schemaLocation="http://指定的uriA test.xsd"> <!--xml文件体--> <名称空间:元素> ... ... </名称空间:元素> </名称空间:根元素> |
说明:
名称空间指向uri1, uriA包含在test.xsd文件中,test.xsd文件复合uriB的标准。
“名称空间”: 自定义的名称
“uriA”: 在xsd文件中指定的路径
“uriB”: 一般是w3c指定的schema约束文件母体:www.w3.org/2001/XMLSchema-instance
2. xsd文件基本构造:
编写风格同xml文件一样,保存为test.xsd文件即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
<?xml version="1.0"?> <前缀:schema xmlns:前缀="http://www.w3.org/2001/XMLSchema" targetNamespace="http://指定的uriA" xmlns="http://指定的uriA" elementFormDefault="qualified"> <!--xsd约束体 --> <前缀:element name='根元素' > <前缀:complexType> <!--数据类型:复杂类型--> <前缀:sequence maxOccurs='unbounded' > <!--按指定出现顺序 任意次数--> <前缀:element name='一级子元素' > <前缀:complexType> <!--数据类型:复杂类型--> <前缀:sequence> <!--按指定出现顺序 --> <前缀:element name='子元素' type='前缀:简单数据类型'/> <前缀:element name='子元素' type='前缀:简单数据类型'/> <前缀:attribute name='属性名' type='前缀:string'/> </前缀:sequence> </前缀:complexType> </前缀:element> </前缀:sequence> </前缀:complexType> </前缀:element> </前缀:schema> |
说明:
“前缀”: 一般默认xs,规定来自命名空间 "http://www.w3.org/2001/XMLSchema"(未命名空间)的元素和数据类型应该使用前缀 xs。
“targetNamespace”: 被此schema定义的元素来自 目标命名空间 uriA。
“elementFormDefault”: 有作用域的,并且是被继承的,除非在子定义中覆盖父定义。
1)qualified: 任何使用此schema约束中声明过的元素的xml文件都必须被此命名空间限定。
2)unqualified: 除了全局元素或者类型将归于目标命名空间外,局部元素将归于无名命名空间。
“element”: 声明xml中的元素,使用“name”指定元素名称。
“complexType”: 指明上面刚声明的元素为复杂数据类型。此元素可以包含子元素,并使用指示器。
“sequence”: Order指示器。用于定义元素的出现顺序。
order指示器:
1)all : 配合Occurrence指示器使用
2)choice : 在给出的子元素里选择某个出现即可
3)sequence : 按照当前特定的顺序出现
“maxOccurs”: Occurrence指示器。用来定义元素出现的次数。
occurrence指示器:
maxOccurs :可出现的最大次数,默认1。unbounded表示不受限制。
minOccurs :可出现的最小次数,默认1。unbounded表示不受限制。
“简单数据类型”: 仅包含文本的元素。它不会包含任何其他的元素或属性。使用“type”声明。
常用简单数据类型
①xs:string 字符串
②xs:decimal 浮点型
③xs:integer 整型
④xs:boolean 布尔值
⑤xs:date 日期
⑥xs:time 时间
默认值和固定值:
①当在xml中没有被设定为其它值时,默认值就会自动分配给元素
<xs:element name="color" type="xs:string" default="默认值"/>
②固定值同样会自动分配给元素,并且您无法设定为其它值。
<xs:element name="color" type="xs:string" fixed="固定值"/>
“attribute”:上面刚声明的元素的属性。
常用属性类型:同上面元素的6个简单数据类型。
默认值:当没有其他的值被规定时,默认值就会自动分配给元素。
<xs:attribute name="属性名" type="xs:简单数据类型" default="默认值"/>
固定值:固定值同样会自动分配给元素,并且您无法规定另外的值。
<xs:attribute name="属性名" type="xs:简单数据类型" fixed="固定值"/>
可选性:默认属性可无。如需规定必须有属性则使用"use":
<xs:attribute name="属性名" type="xs:简单数据类型" use="required"/>
3.使用默认名称空间:
仅在xml中使用xmlns引入一次即可。
|
1 2 3 4 5 6 7 8 9 10 |
<根元素 xmlns="http://指定的uriA " xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="指定的uriA test.xsd"> <一级子元素> <子元素>元素体</子元素> <子元素>元素体</子元素> </一级子元素> <根元素> |
4.不使用名称空间
不用在xml文件中引入名称空间,仅使用未命名空间
|
1 2 3 4 5 6 7 8 9 10 |
<?xml version="1.0" encoding="UTF-8"?> <根元素 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="莫须有的xsd文件"> <一级子元素> <子元素>元素体</子元素> <子元素>元素体</子元素> </一级子元素> </根元素> |
四。XML解析
1.XML解析方式分为两种:dom和sax
1. dom:(Document Object Model, 即文档对象模型)是W3C组织推荐的处理XML的一种内存加载方式。
2. sax:(Simple API for XML)使用事件触发机制,XML社区的标准,几乎所有的XML解析器都支持它。
2.XML解析器(引擎):
操作xml文件的底层系统,都支持上面的两种解析方式
1. Crimson(sun):性能最次,但它是标准
2. Xerces(IBM):性能较好
3. Aelfred2(dom4j) :性能最好
3.XML解析开发包(API):
将解析器封装已便于使用
1. Jaxp(sun):支持两种方式(DOM和SAX)对XML文档进行解析
2. dom4j(全新的api):性能优异、功能强大和极易使用
3. pull解析(Andriod的sdk自带pull解析):采用事件触发的方式解析 xml 文档
4.Jaxp解析:
使用附上的demo.xml文件
1)dom方式:
(1)查询:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
//1. 创建xml对象制造工厂 DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance(); //2. 创建xml对象解析器 DocumentBuilder builder = factory.newDocumentBuilder(); //3. 解析指定xml文档 Document document = builder.parse("src/demo.xml"); //4. 获取第一个一级子元素的节点集合 NodeList nodeList = document.getElementsByTagName("student"); //5. 获取集合中的第一个节点 Node firstNode = nodeList.item(0); //6. 获取第一个节点的子节点。包括换行 Node firstChildNode = firstNode.getFirstChild(); //7. 获取下一个子节点 Node secondChildNode= firstChildNode.getNextSibling(); //8. 获取节点的文本 String textContent = secondChildNode.getTextContent(); System.out.println("第一个学生的姓名是:"+textContent); |
(2)插入:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
//1.获取xml对象 Document document = DocumentBuilderFactory.newInstance().newDocumentBuilder().parse("src/demo.xml"); //2.获取指定的节点 Node firstNode = document.getElementsByTagName("student").item(1); //3.新建一个元素 Element newElement = document.createElement("nickName"); //4.元素值 newElement.setTextContent("阿凤"); //5.在节点内添加新元素 firstNode.appendChild(newElement); //6.转换器 Transformer transformer = TransformerFactory.newInstance().newTransformer(); //7.写入xml文件 transformer.transform(new DOMSource(document), new StreamResult("src/demo.xml")); //查询 String string = firstNode.getTextContent(); System.out.println("第一个学生的信息是:"+string); |
2)sax方式:只能做读取且仅读取一次
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
public class SaxDemo { public static void main(String[] args) throws Exception { //1. 获得解析器 SAXParser saxParser = SAXParserFactory.newInstance().newSAXParser(); //2. 获得读取器 XMLReader xmlReader = saxParser.getXMLReader(); //3. 绑定内容处理器 xmlReader.setContentHandler(new XmlHandler()); //4. 解析xml文件 xmlReader.parse("src/demo.xml"); } } class XmlHandler extends DefaultHandler { private boolean roll = false; //控制遍历次数 private int num = 0; @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { //读到开始标签时触发此方法 // 当读到student开始标签时 b 置为true if ("student".equals(qName)) { roll = true; num++; } System.out.print("start:"+qName); } @Override public void characters(char[] ch, int start, int length) throws SAXException { if (b && num == 2) { String data = new String(ch, start, length); System.out.print(data); //会读取换行 } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { //读到结束标签触发此方法 // 当读到student结束标签时 b 置为false if ("student".equals(qName)) { roll = false; } System.out.print("end:"+qName); } } |
5.Pull解析:
须要使用独立的jar包:
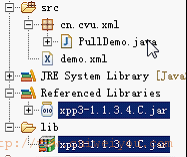
代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
//1. 创建工厂 XmlPullParserFactory factory = XmlPullParserFactory.newInstance(); //2. 创建解析器 XmlPullParser parser = factory.newPullParser(); //3. 引入xml文件 parser.setInput(new FileInputStream("src/demo.xml"), "UTF-8"); //4. 声明解析事件 int i = parser.getEventType(); //5. 计数器 int num=1; //5. 执行解析(如果没有读到末尾) while(i != parser.END_DOCUMENT){ switch (i){ //开始读取 case XmlPullParser.START_TAG: //次级子元素(仅查询第二个学生) if("name".equals(parser.getName()) && num++==2) System.out.println(parser.nextText()); break; default: break; } //下一个一级子元素 i=parser.next(); } |
6.DOM4J解析:
须要使用独立的jar包:
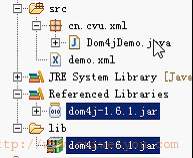
1)查询:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
//1. 读取器 SAXReader reader = new SAXReader(); //2. 对象 Document document = reader.read("src/demo.xml"); //3. 根节点 Element rootElement = document.getRootElement(); //4. 一级子节点 Element elementStudent = rootElement.element("student"); //5. 获得子节点 Element elementName = elementStudent.element("name"); System.out.println("第一个学生的姓名:"+elementName.getText()); //6. 获得全部学生 List list = rootElement.elements("student"); //7. 获得第一个学生(从0始) Element student = (Element) list.get(1); //8. 获得第一个学生的name Element name = student.element("name"); System.out.println("第二个学生姓名:"+name.getText()); //9. 获得第一个学生的姓名的属性 Element name2 = rootElement.element("student"); String examid = name2.attributeValue("examid"); System.out.println("第一个学生的姓名属性:"+examid); Element elementName2 = name2.element("name"); String examidName = elementName2.attributeValue("examid"); System.out.println("第一个学生的姓名的姓名属性:"+examidName); |
2)添加:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
//1. 读取器 SAXReader reader = new SAXReader(); //2. 对象 Document document = reader.read("src/demo.xml"); //3. 根节点 Element rootElement = document.getRootElement(); //4. 一级子节点 Element elementStudent = rootElement.element("student"); //5. 创建新元素 Element newElement = DocumentHelper.createElement("sex"); newElement.setText("男"); //6. 添加 elementStudent.add(newElement); /* //7. 准备xml文件 Writer writer = new OutputStreamWriter(new FileOutputStream("src/demo.xml"), "UTF-8"); //8. 写入文件 document.write(writer); //9. 关闭流 writer.close(); */ // 快捷添加 elementStudent.addElement("age").addAttribute("ageId", "23").addText("我23岁"); // 使用美化格式写入 OutputFormat format=OutputFormat.createPrettyPrint(); XMLWriter writer=new XMLWriter(new FileOutputStream("src/demo.xml"), format); writer.write(document); writer.close(); |
3)修改:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SAXReader reader = new SAXReader(); Document document = reader.read("src/demo.xml"); Element rootElement = document.getRootElement(); //1. 获得指定的全部子元素 List students = rootElement.elements("student"); //2. 选择第二个student元素(始于0) Element student = (Element) students.get(1); //3. 获得其name元素 Element name = student.element("name"); //4. 修改元素体 name.setText("张大三四五六"); // 使用美化格式写入 OutputFormat format=OutputFormat.createPrettyPrint(); XMLWriter writer=new XMLWriter(new FileOutputStream("src/demo.xml"), format); writer.write(document); writer.close(); |
7. XPath&DOM4J:
1)导入一个新的jar包:
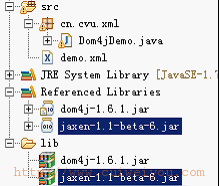
2)代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SAXReader reader = new SAXReader(); Document document = reader.read("src/demo.xml"); //1. 使用XPath得到school下全部的student元素,无论父子/父孙关系 List students = document.selectNodes("//school/student"); //2. 选择第二个student元素(始于0) Element student = (Element) students.get(1); //3. 获得其name元素 Element name = student.element("name"); //4. 修改元素体 name.setText("四五六"); // 使用美化格式写入 OutputFormat format=OutputFormat.createPrettyPrint(); XMLWriter writer=new XMLWriter(new FileOutputStream("src/demo.xml"), format); writer.write(document); writer.close(); |
3)常用XPath:
①得到根元素AAA:
document.selectNodes("/AAA");
②得到AAA中子元素DDD的全部BBB子元素:
document.selectNodes("/AAA/DDD/BBB"); //匹配的BBB
document.selectSingleNode("/AAA/DDD/BBB"); //第一个BBB
③得到全部的BBB元素:无论层级关系:
document.selectNodes("//BBB"); //全部的BBB
④得到全部的父元素是DDD的BBB元素:
document.selectNodes("//DDD/BBB"); //全部的BBB
⑤得到全部的路径依附于/AAA/CCC/DDD的元素:
document.selectNodes("/AAA/CCC/DDD/*"); //DDD内全部的子元素
⑥得到全部的拥有3个父级元素的BBB元素:
document.selectNodes("/*/*/*/BBB"); //匹配的BBB
⑦得到xml文件中全部元素:
document.selectNodes("//*");
⑧得到AAA的第一个BBB子元素:
document.selectNodes("/AAA/BBB[1]"); //匹配的BBB
⑨得到AAA的最后一个BBB子元素:
document.selectNodes("/AAA/BBB[last()]"); //匹配的BBB
⑩得到有id属性的BBB元素:
document.selectNodes("//BBB[@id]"); //匹配有id属性的BBB
得到有任意属性的BBB元素:
document.selectNodes("//BBB[@*]"); //匹配有任意属性的BBB
得到全部没有属性的BBB元素:
document.selectNodes("//BBB[not(@*)]"); //匹配任意没有属性的BBB
得到含有属性id且其值为'b1'的BBB元素:
document.selectNodes("//BBB[@id='b1']"); //匹配有属性id且值为bi的BBB
得到含有2个BBB子元素的元素:
document.selectNodes("//*[count(BBB)=2]"); //匹配 含有两个BBB子元素 的元素
得到含有3个子元素的元素:
document.selectNodes("//*[count(*)=3]"); //匹配 含有任意三个子元素 的元素
得到全部名称为BBB的元素(这里等价于//BBB):
document.selectNodes("//*[name()='BBB']"); //匹配 元素名为BBB 的元素
得到全部名称以"B"起始的元素:
document.selectNodes("//*[starts-with(name(),'B')]"); //匹配 元素名第一个字母为B 的元素
得到全部名称包含"C"的元素
document.selectNodes("//*[contains(name(),'C')]"); //匹配 元素名包含字母C 的元素
8.XStream解析:
导入独立的jar包:
xmlpull-*.jar
xpp3_min-*.jar
xstream-*.jar
1)写出xml文件:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
@Test public void write() throws Exception { //使用JavaBean准备演示数据 List<Book> allBook = new ArrayList<Book>(); allBook.add(new Book("Java基础", "vigiles", "¥29")); allBook.add(new Book("Java进阶", "vigiles", "¥39")); allBook.add(new Book("Java高级", "vigiles", "¥49")); allBook.add(new Book("Java顶级", "vigiles", "¥59")); // 1。 xml操作对象 XStream xStream = new XStream(); // 2。设置对应元素名 // 根元素 xStream.alias("allbook", List.class); // 子元素 xStream.alias("book", Book.class); // 属性 xStream.aliasAttribute(Book.class, "title", "title"); // 3。 写出xml文件(内容,目标) xStream.toXML(allBook, new FileOutputStream(new File("book.xml"))); } |
2)读取xml数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@Test public void read() { XStream xstream = new XStream(); xstream.alias("allbook", List.class); xstream.alias("book", Book.class); xstream.aliasAttribute(Book.class, "title", "title"); //读取xml List<Book> allBook = (List<Book>) xstream.fromXML(new File("book.xml")); System.out.println(allBook); } |
附:xml文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
<?xml version="1.0" encoding="UTF-8" ?> <school> <student name="1" examid="a1"> <name>张三</name> <location>沈阳</location> <grade>89</grade> </student> <student name="2" examid="a2"> <name>王五</name> <location>邯郸</location> <grade>68</grade> </student> <student name="333" examid="444"> <name>李四</name> <location>大连</location> <grade>97</grade> </student> </school> |
本文由崔维友 威格灵 cuiweiyou vigiles cuiweiyou 原创,转载请注明出处:http://www.gaohaiyan.com/1470.html
承接App定制、企业web站点、办公系统软件 设计开发,外包项目,毕设



